What is Azure Data Factory?

Azure Data Factory is a cloud-based data integration platform from Microsoft. It allows organizations to gather data from multiple sources and perform various data engineering operations in a code-free way.
For organizations struggling to manage and extract insights from exponentially increasing amounts of data, ADF can be a more efficient and cost-effective way to do that. In this post, I’ll explain in detail what Azure Data Factory is and how its major components work. It’s a featured-packed platform, but this guide will help you identify the best use cases for your business.
What is Azure Data Factory?
Azure Data Factory (ADF) is a cloud-based data pipeline orchestrator and data engineering tool. It’s part of Microsoft’s Azure cloud ecosystem and you can access it on the web.
There are currently two versions of ADF, version 1 and version 2. In this article, we’ll be covering the version 2 of the platform, which added support for more data integration scenarios.
A cloud-based data integration platform
Azure Data Factory is a fully-managed serverless data integration platform. It can help organizations build data-driven workflows by integrating data from multiple heterogeneous sources.
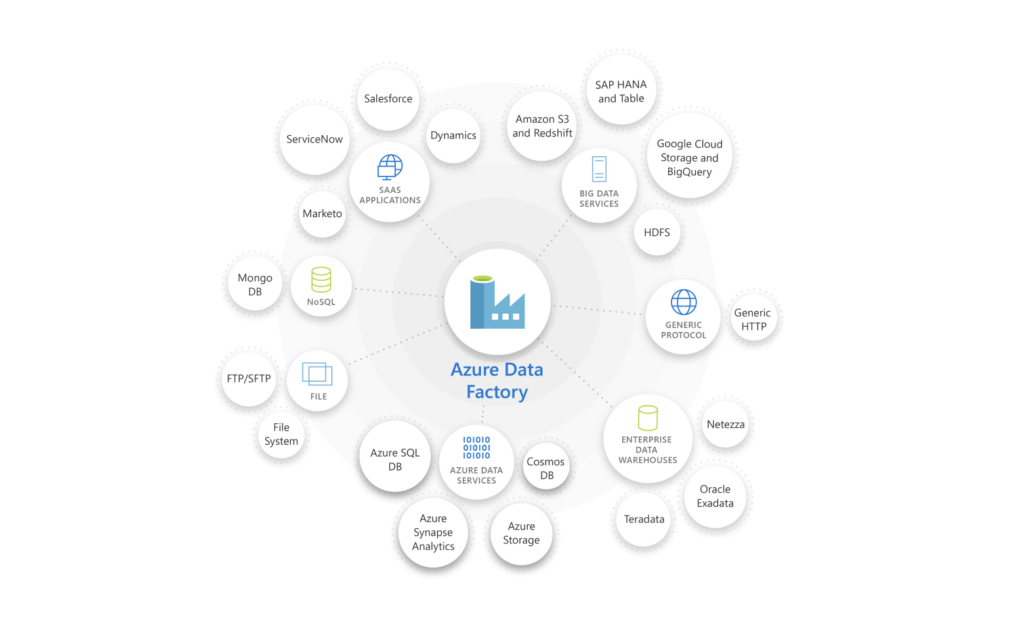
With over 100 different built-in and easy-to-maintain data connectors, you can build scalable and reusable pipelines that integrate different data sources, all without having to code. ADF lets you extract data from on-premises, hybrid, or multi-cloud sources. You can load all of it into your data warehouse or data stores for transformation.
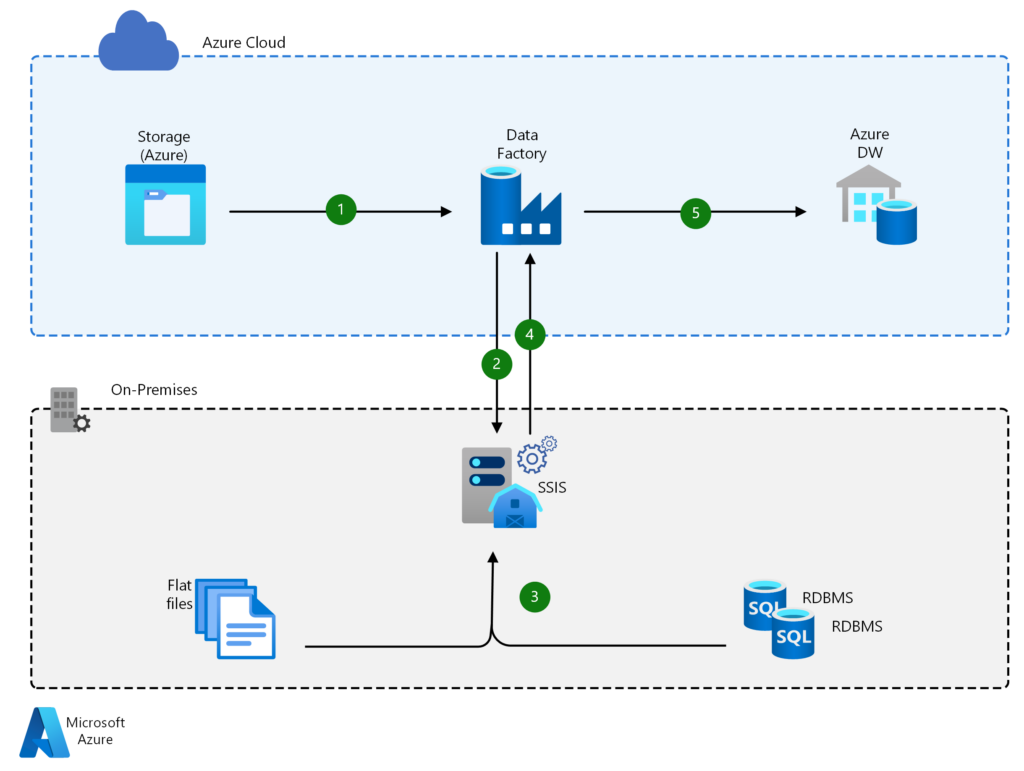
ADF also provides an easy-to-use console to track data integrations and monitor overall system performance in real time. The platform also lets companies extend and rehost their Azure SQL database and SQL Server Integration Services (SSIS) in the cloud in a few clicks.
A data engineering service
On top of serving as a data integration platform, ADF is also a data engineering service. It allows organizations to extract value out of structured, unstructured, or semi-structured data in their data stores. By passing this data to downstream compute services, such as Azure Synapse Analytics, businesses can get insights on how to tackle operational challenges.
How does Azure Data Factory work?
To better understand how ADF works, let’s take a look at what happens during the data integration and data engineering stages.
Connecting and collecting data
Azure Data Factory offers over 100 different connectors to integrate data from on-premises, cloud, or hybrid sources. Outside of the Azure ecosystem, ADF supports the main Big Data sources including Amazon Redshift, Google BigQuery, Oracle Exadata, and Salesforce. As we previously mentioned, ADF also lets you create pipelines to extract data on specific intervals that can be scheduled.
Data consolidation
All data collected by ADF is organized in clusters. These clusters can either be stored in a single cloud-based repository or a data store like Azure Blob storage for downstream processing and analysis.
Data transformation
Once your extracted data has been transferred to a centralized data store, it can be transformed using different and configurable ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) solutions. You can use services like Azure Data Lake Analytics, Azure Synapse analytics, Azure HDInsight, Spark, Hadoop, and more.
Data publishing
After processing and transforming your data, it can now be published for consumption, archiving, or analytical purposes. ADF offers full support for Continuous Integration and Continuous Deployment (CI/CD) of your data pipelines using Azure DevOps and GitHub.
Monitoring
Lastly, you can use the Azure Monitor REST API or PowerShell to monitor your workflows and data pipelines connected to external data sources. ADF also generates logs that can be configured to set up alerts for errors in a workflow.
Core components of Azure Data Factory
Azure Data Factory relies on several core components that work together to let you create data integration pipelines in a code-free manner. We’re going to detail all of them here.
Pipelines and pipelines runs
In ADF, a pipeline is a group of activities designed to perform a specific task. A pipeline run is an instance of a pipeline execution.
Pipelines in ADF will allow you to group different activities in an efficient way. By creating multiple pipelines, you can also execute different tasks in parallel.
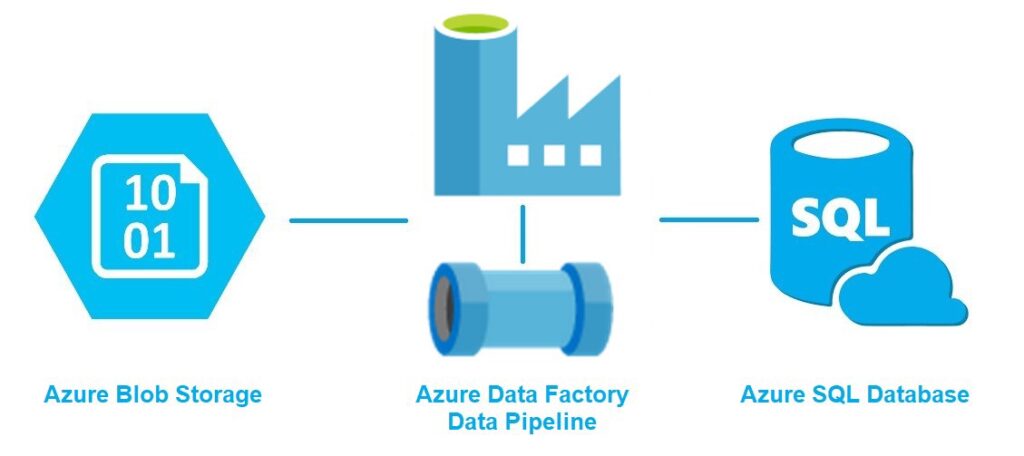
For example, you can create a pipeline to extract data from a source, transform that data into a particular format, and feed it to a different service.
Activities
An activity is a single step in an ADF pipeline. For example, it can be a connection to a data source, or copying data from one source to another.
ADF supports the following three types of activities:
- Data movement activities
- Data transformation Activities
- Data control activities.
Datasets
A dataset is a general collection of data. In ADF, these datasets can be internal and external. They can be used to serve as an input (source) or output (destination) for your pipelines.
Linked services
Linked services are the connection strings that include the configuration and connection information needed for ADF to connect to external resources. Linked services can represent a data store such as an SQL Server database or an Azure Blob storage account. They can also represent a compute resource hosting the execution of an activity, such as an HDInsight Hadoop cluster.
Triggers
A trigger represents the unit of processing that determines when a pipeline or an activity within a pipeline should be executed. ADF allows you to create different types of triggers for different events.
Control flow
Control flow is what defines the execution of pipeline activities in ADF. You can chain activities in a sequence with For-each iterators, and you can also map data flows for sequential or parallel execution.
Benefits of Azure Data factory
Now that we’ve covered the top-level concepts of Azure Data Factory, we’re going to detail how this platform can be useful in the world of big data.
Easy data integrations
As we mentioned earlier, ADF offers more than 100 connectors for integrating data from various systems residing either on-premises or in the cloud.
ADF also lets you easily migrate and upgrade ETL workloads. This also applies to SQL Server Integration Services packages and other on-premises workloads you’d like to move to the cloud.
Code-free data transformation
With its intuitive GUI, Azure Data Factory allows you to easily import and transform data without having to write any code. Data transformation is a usually complex task requiring coding, scripting, and strong analytical abilities. However, ADF can handle complex data integration projects seamlessly.
Scalability
ADF can outperform several traditional ETL solutions that limit the amount and type of data you can process. With its time-slicing and control flow capabilities, ADF can migrate large volumes of data in minutes.
Cost efficiency
ADF provides ETL services in addition to its data integration capabilities. Therefore, you don’t have to pay the licensing fee associated with traditional ETL solutions. Moreover, ADF has a pay-as-you-use model, which mitigates the need for heavy upfront infrastructure costs.
Downstream services
Because ADF belongs to Microsoft’s Azure ecosystem, you can easily integrate it with downstream services such as Azure HDInsight, Azure Blob storage accounts, or Azure Data Lake analytics. In addition to seamless integrations with Azure services, ADF also offers regular security updates and technical support.
Azure Data Factory pricing
Pricing for ADF version 1 is based on the following factors:
- Frequency of activities (e.g: the number of times you will perform data pulls or transformations).
- Whether the activity is performed on-premises or on the cloud.
- The state of your pipelines (active vs inactive).
- The duration of activities.
However, the latest version of ADF (v2) allows users to create more complex data-driven workflows, and there are additional factors impacting the pricing. This includes:
- Data pipeline orchestration and execution.
- Data flow execution and the frequency of debugging.
- The volume of data factory operations.
Pricing will also vary based on your region and the amount of Data Factory operations you need to perform. To estimate your costs, Microsoft provides a price calculation tool on the ADF product page.
Summary
Azure Data Factory is a robust platform for extracting and consolidating data from multiple heterogeneous sources. It can also be used as a data engineering platform to extract value out of different forms of data. For organizations dealing with large amounts of data, ADF can be a cost-effective solution for accelerating data transformation and unlocking new business insights.

Sukesh is a Technical Manager by profession and an IT enterprise and Technology enthusiast by passion. He holds a Master's degree in Software Engineering and has filled in various roles including software development, analysis, consultation, and mana...
