Nvidia Unveils H100 NVL Inference Platform Optimized for Large Language Model Deployments

Nvidia unveiled this week four new inference platforms optimized for generative AI applications such as OpenAI’s ChatGPT. The new platforms include Nvidia’s latest GPU innovations and inference software to deliver optimal performance for AI-based workloads such as large language model (LLM) deployment, image creation, and AI-powered video.
“The rise of generative AI is requiring more powerful inference computing platforms,” said Jensen Huang, founder and CEO of NVIDIA. “The number of applications for generative AI is infinite, limited only by human imagination. Arming developers with the most powerful and flexible inference computing platform will accelerate the creation of new services that will improve our lives in ways not yet imaginable.”
For those unfamiliar with it, AI inferencing is what happens after a neural network has been trained using existing data. The next step is to confront this trained neural network to real-world data and see if it can successfully apply what it previously learned to this new data.
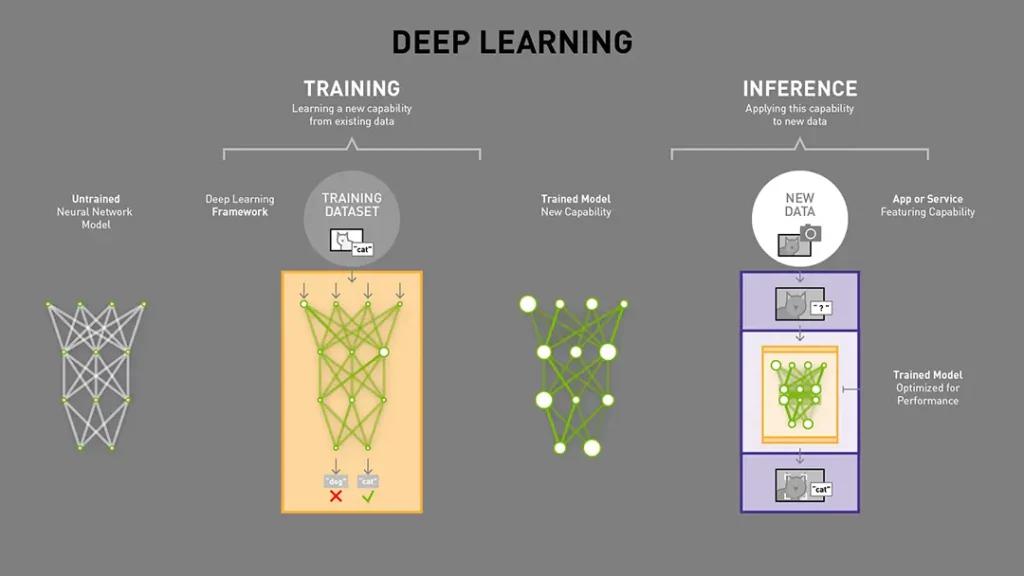
Just like deep neural network training, AI inferencing requires a lot of GPU power. However, Nvidia has a new H100 NVL platform that’s optimized for generative AI inference workloads.
NVIDIA’s H100 NVL inference platform is optimized for Large Language Model Deployments
The Nvidia H100 NVL is one of the four new inference platforms that Nividia announced earlier this week. “The new H100 NVL with 94GB of memory with Transformer Engine acceleration delivers up to 12x faster inference performance at GPT-3 compared to the prior generation A100 at data center scale,” Nvidia said.
If Nvidia’s H100 NVL platform won’t be available until the second half of 2023, the chip maker said that it’s “ideal for deploying massive LLMs like ChatGPT at scale.” Cohere, a Canadian startup working on natural language processing models is one of the companies that’s already testing Nvidia’s new inference platform ahead of its general availability.
“NVIDIA’s new high-performance H100 inference platform can enable us to provide better and more efficient services to our customers with our state-of-the-art generative models, powering a variety of NLP applications such as conversational AI, multilingual enterprise search and information extraction,” said Aidan Gomez, CEO at Cohere.
The three other inference platforms Nvidia announced this week include the Nvidia L4 GPU for AI video, which is already available in private preview on the Google Cloud Platform. Lastly, the Nvidia L40 GPU for image generation is already available from leading manufacturers, while the Nvidia Grace Hopper superchip for recommendation models will start shipping in the second half of 2023.

Laurent was the Editorial Manager of the Petri IT Knowledgebase from 2022-2023. He's currently the Senior News Editor of Thurrott.com.