Network Requirements for Azure Stack HCI Active/Active Cluster Nodes

Today I want to explain some more details about the maximum possible distance between two Azure Stack HCI nodes within an active/active cluster.
As you may know, Azure Stack HCI has two cluster options, active/active or stretched cluster. A standard active/active cluster, with at least two server nodes in a single site or the same server rack, is the recommended setup.
The other option is a so-called ‘stretched cluster‘. It has at least four server nodes that span across two sites, and at least two nodes per site.
Many customers are asking if they can add more nodes to a standard cluster. And if they can deploy a standard cluster over a larger distance than one single location or data center.
The short answer is yes. That is possible. But you need to follow some hard guidelines.
Guidelines for Azure Stack HCI standard clusters
After some discussion with Microsoft Product Groups, we found out that there are some pretty good and understandable requirements at the networking level for standard cluster nodes.
Network latency
First, let’s start with the latency requirements. Between two nodes, Azure Stack HCI expects a high-performance, low latency connection. In numbers, that means the latency between two nodes must be less than one millisecond and a minimum speed of 25 Gbit/s or more is required.
Another major requirement is to avoid asymmetry latency between nodes. The connection between the HCI nodes must be non-routed, which means only a switch connection between nodes and both HCI nodes must be in the same subnets.
These two requirements make wide area network (WAN) deployments quite complex, as you need to deploy direct layer 2 WAN links that are bridging the same distance. As nearly every network service provider deploys and configures WAN circuits to be redundant and not taking the same routes, it is impossible to not end up with asymmetric latency.
From an active/active cluster deployment view, it also makes the most sense to deploy on the same office, building, or within the same metropolitan area.
Please be aware that Microsoft still recommends having all cluster nodes in one server rack, even if more deployment options are possible.
Possible deployments
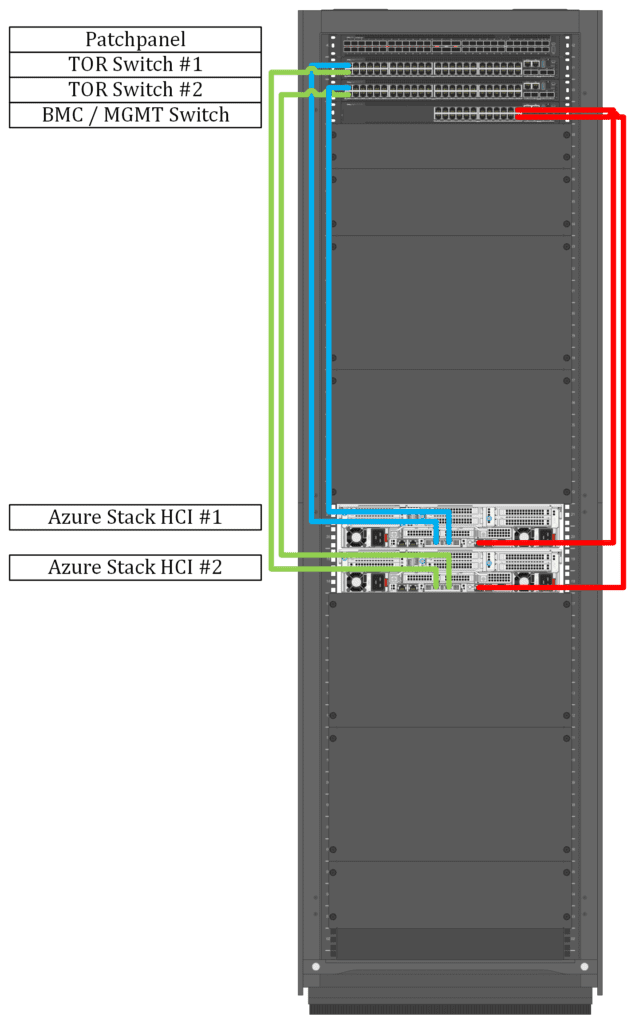
An additional deployment guideline is to use two top-of-rack (ToR) switches and two interconnect uplinks per server. One uplink is connected to ToR switch one and the other connection to ToR switch two.
If you have a single rack
Within a single rack, the deployment would look like the diagram below.
Deployment options over larger distances
If you want to deploy an Azure Stack HCI active/active cluster over a larger distance, there are basically two options you could try.
One ToR switch per location
- The cheapest option would be to deploy one ToR switch in location one, and the other ToR switch in the second location. One server link is connected to the ToR switch locally and the other one is connected via WAN Link to the remote ToR switch.
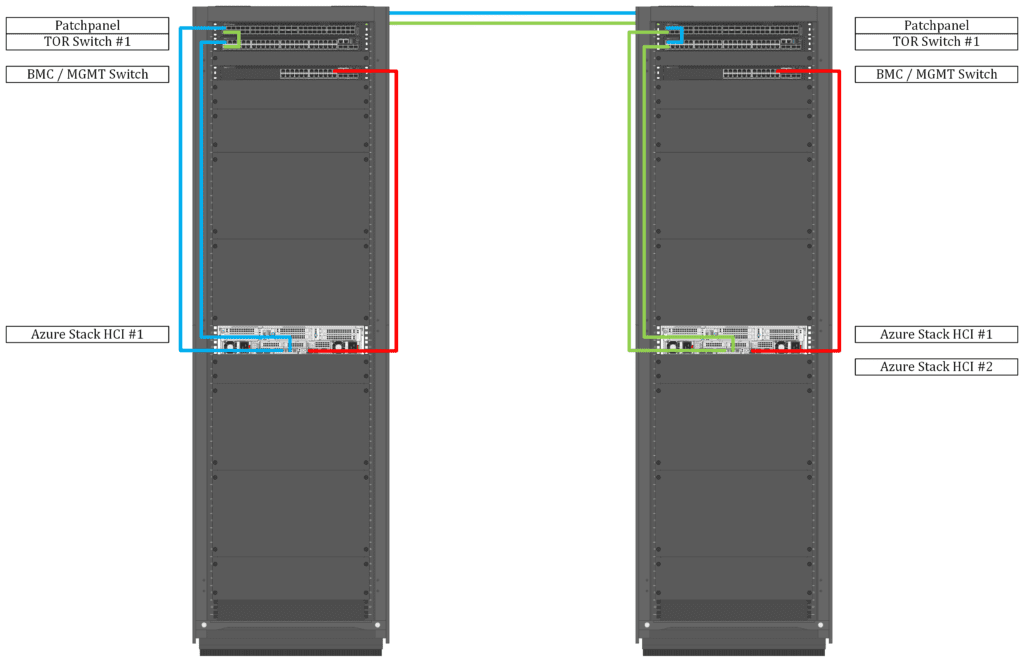
This setup requires one WAN Link per server, and it is most likely not feasible for more than two servers.
Two ToR switches per location
The other option is to deploy four ToR switches, two per location, and connect the ToR switches with the required amount of WAN links. For redundancy, there should be a minimum of two links, but for larger clusters, you would require more capacity. So, it makes sense to use Links with 50 Gbit/sec or above.
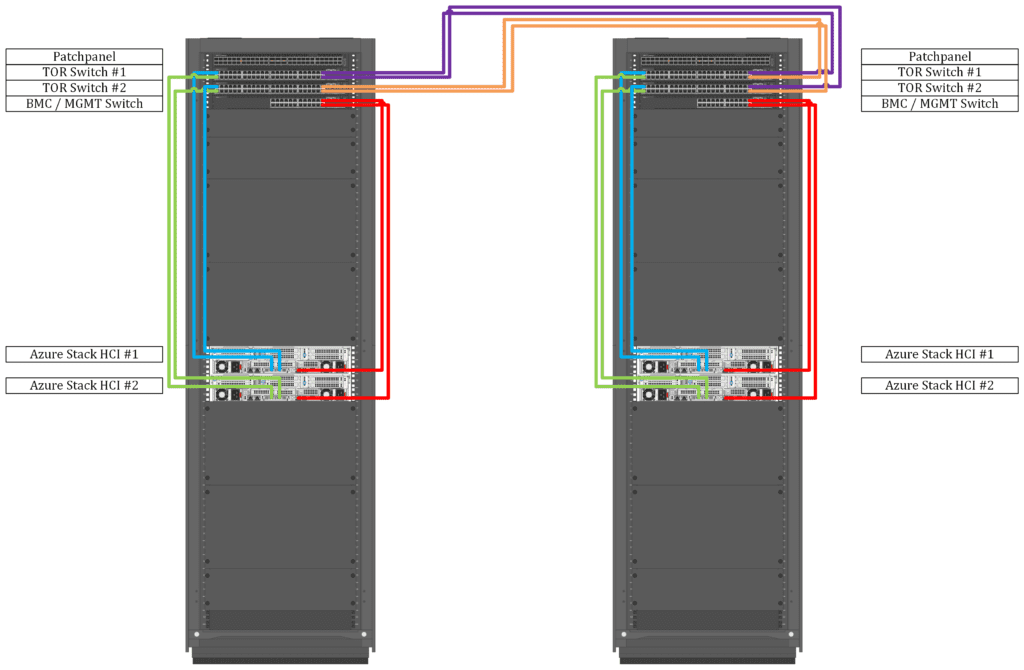
Here it is important to keep latency as symmetric as possible and stay beneath one millisecond.
How to maintain virtual machine redundancy
When using an active/active cluster, one important issue you’ll have to deal with is how to maintain virtual machines and virtual machine clusters highly available between sites. You may want to avoid virtual machines, which belong to a cluster, failing at the same time.
To avoid such outages and to ensure that both virtual machines will be offline at the same time, you can set up VM affinity rules using PowerShell.
If you are using System Center Virtual Machine Manager 2019 or later, you can also use virtual machine settings to configure preferred and possible owners of virtual machines and availability sets for those virtual machines.
Things to keep in mind
There are a few things you should always keep in mind.
Software Defined Networking (SDN) considerations
If you use Software Defined Networking (SDN) and converge all traffic into two 25 Gbit/sec physical network interfaces, for example, you might not have enough throughput capacity. So, it makes sense to use larger interfaces, (48 Gbit/sec and higher), or use dedicated network interfaces. For example, you can separate interfaces for management, storage, and virtual machine access.
Remote Direct Memory Access (RDMA)
As Azure Stack HCI with Storage Spaces Direct requires Remote Direct Memory Access (RDMA), you need to be aware of the protocol you want to use. Currently, there are two protocols out there. iWARP, which is simple to implement but with lower performance and it is not routable. And RoCE (RDMA over Converged Internet), which has better performance but your switches need to support Datacenter Bridging (DCB).
If you want to learn more about Remote Direct Memory Access, I would recommend Intel’s product brief about iWARP and RDMA.
Configuration of affinity and placement rules
You may want to automate the configuration of affinity and placement rules. You could for example set up a task on one of your management hosts that scans your host for specific names like DC-01 and DC-02. Using those names, you would then configure your affinity and placement rules.
Lastly, if you are spreading out your cluster nodes, please set up proper monitoring and configure alerts and warnings so that you are notified as soon as the given thresholds and warning levels are reached.
Summary
It is still recommended to have all active/active cluster nodes in one rack to reduce external impact. But when staying within the guidelines set by Microsoft, you can build a much more flexible Azure Stack HCI deployment.
When following Microsoft’s guidelines, you can easily “stretch” an active/active cluster through your campus without using the actual stretch clustering option. Please plan carefully for high availability and virtual machine placements in those environments. Also keep network monitoring and storage replication a high priority, as you may stretch your cluster to its limits.
Lastly, I invite you to check out the network requirement changes in Azure Stack HCI Version 22H2.
Related Article:

Flo Fox spend nearly 10 years with Microsoft as Sr. Engineer and Priority Area Lead at Microsoft before leaving the company in 2025. Currently he is working as a Area Lead for Infrastructure at itacs GmbH (itacs – Einfach leicht machen.) in Germany...


