What is Amazon Kinesis Data Firehose?

Amazon Kinesis Data Firehose is a fully managed service for efficiently streaming data from virtually any data source to your AWS applications. It provides near-real-time ingestion capabilities for building real-time data applications. In this article, we’ll detail how Amazon Kinesis Data Firehose works and the best use cases for it.
What is Amazon Kinesis Data Firehose?
Amazon Kinesis Data Firehose is a fully-managed streaming ETL (extract, transform, and load) service that can ingest streaming data from various sources, optionally transform it into new formats and deliver it into data lakes and data warehouses for analysis. It can combine data from multiple sources such as AWS EC2 or AWS DynamoDB, transform it for analytics purposes, and then load it to destination services such as Amazon S3, Amazon Redshift, Splunk, or other HTTP endpoint partners.
Let’s dive into what happens during the extract, transform, and load processes.
Ingesting data from multiple sources
Amazon Kinesis Data Firehose can capture logs, financial data, sales orders, and other types of data. Data Sources can include logs coming from Amazon EC2 instances or data from mobile apps and IoT devices.
There are different ways to connect data sources to Amazon Kinesis Data Firehose:
- The Amazon Kinesis Data Firehose API: leverages AWS SDK for Java, .NET, Node.js, Python, or Ruby to send data to a Kinesis Data Firehose delivery stream.
- Amazon Kinesis Data Streams: This serverless streaming data service can capture and load data into Amazon Kinesis Data Firehose
- Native integrations: AWS Cloudwatch, AWS EventBridge, AWS IoT, and AWS Pinpoint are data sources that are supported natively.
- The Amazon Kinesis Agent: can be installed in Linux-based server environments to collect and send data.
- AWS Lambda: Developers can write Lambda functions to send data to the platform.
Transforming data
If needed, customers can transform the extracted data into a specific format to make it more usable. Again, there are various ways to do that.
Firstly, Amazon Kinesis Data Firehose has built-in transformation options for raw and JSON data. This data can be transformed into formats such as Apache Parquet and Apache ORC formats.
Developers can also use AWS Lambda functions to transform raw data when creating a new delivery stream. You can create a function from scratch or leverage Lambda blueprints provided by AWS.
Lastly, the platform can compress data before loading it to Amazon S3. With dynamic partitioning, customers can also optimize data for analytics tools.
Loading real-time streaming data
After extracting and transforming data, Amazon Kinesis Data Firehose can load it to various sources for analytics purposes, including:
- Amazon S3 buckets to store data as gzip formatted logs using AWS S3 APIs.
- Amazon Redshift: Data warehouse service in the AWS cloud allows you to store data and query it instantly regardless of its size.
- Amazon OpenSearch Service: Service for enabling search capabilities
- Splunk: Real-time DevOps monitoring platform.
- Datadog: A monitoring and analytics tool that provides performance metrics and event monitoring for all data center-related infrastructures and public cloud services.
- Dynatrace: A monitoring tool for real-time monitoring of network processes, users, and more.
- New Relic: A cloud-based full stack observability platform.
- Sumo Logic, LogicMonitor, MongoDB, and other HTTP endpoints are also supported destinations.
What are the benefits of using Amazon Kinesis Data Firehose?
For organizations looking for a streamlined ETL solution, Amazon Kinesis Data Firehose can offer a lot of benefits with no code required.
A fully managed service
Because Amazon Kinesis Data Firehose is a fully managed service, customers don’t have to worry about its underlying infrastructure. The ETL service can automatically scale to capture and load more data, and it also offers high availability by replicating data across three data centers in the same AWS region.
Pay-as-you-go pricing
You can get started for free with Amazon Kinesis Data Firehose and only pay for the following 4 types of on-demand usage:
- Ingestion: You’ll be billed per GB ingested in 5KB increments, but ingestion pricing will depend on the data center region you choose. Moreover, the price will vary depending on if you use the Direct PUT option and Kinesis Data Stream as a source or use records coming from Vended Logs as a source (more expensive). Vended Logs are service logs natively published by AWS services.
- Format conversion: In this optional step, the price per ingested GB converted is $0.018 (US East region).
- VPC Delivery: You can choose to deliver data streams in a virtual private cloud (VPC), but this is optional. If you choose to do so, the price per GB processed into a VPC is $0.01 (US East region).
- Dynamic partitioning: This is also an optional add-on for data delivered to Amazon S3. The price per GB delivered is $0.02 (US East region).
Optional automatic encryption
Amazon Kinesis Data Firehose offers two types of encryption for data at rest and data in transit. Data is in transit when it’s moving from one place to another destination, such as an Amazon S3 bucket.
When configuring a delivery stream, you can choose to encrypt your data using an AWS Key Management Service (KMS) key, which you control and manage. While encrypting your data is optional, it’s recommended to improve security.
How does Amazon Kinesis Data Firehose work?
To show you how to get started with this platform, I’ll explain how to create a Kinesis Data Firehose delivery stream to send data to the destination of your choice.
Creating a Kinesis Data Firehose delivery stream
To create a Kinesis Data Firehose delivery stream, we’ll need to choose a data source and a delivery stream destination. Before you get started, however, here’s what you’ll need:
- Sign in to the AWS Management Console.
- Create an IAM role with Kinesis permissions or an IAM user with permissions to create and manage a Kinesis Data Firehose delivery stream.
- Have AWS credentials configured for the IAM user.
Now, the first step is to log in to the AWS Management console and open the Kinesis console as shown below.
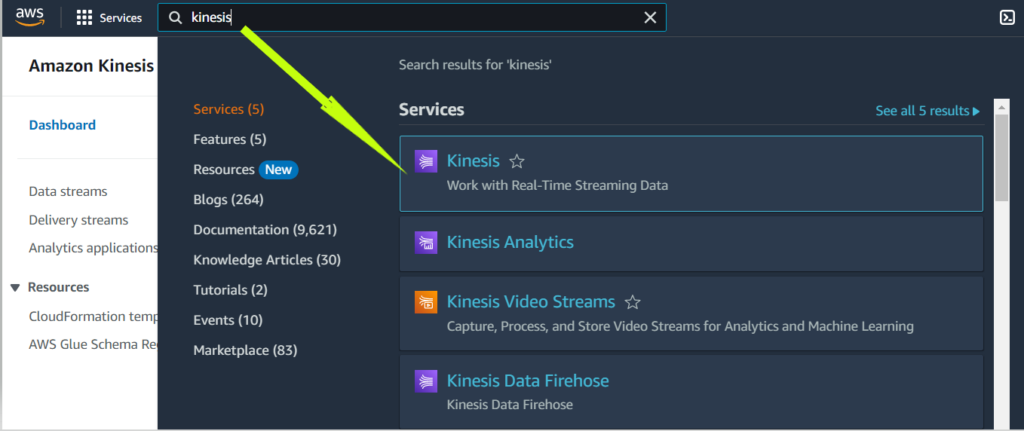
- Next, select the Kinesis Data Firehose option and click on Create delivery stream.
[Image2]

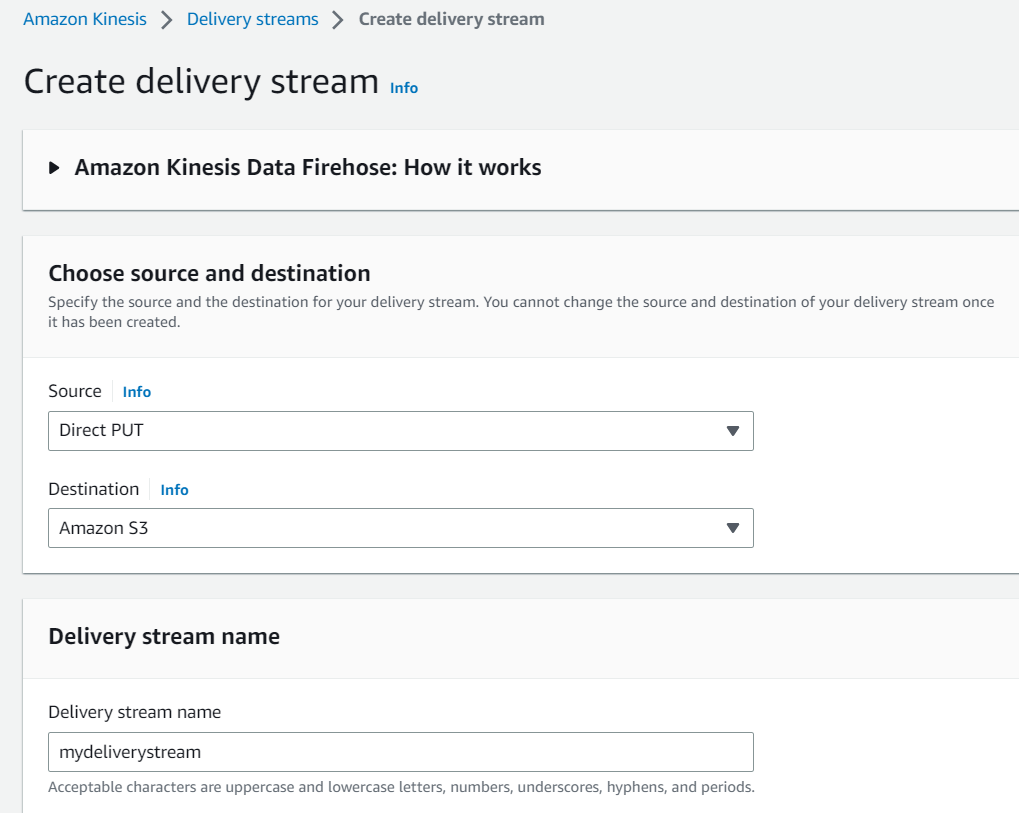
- Now, in the ‘Choose source and destination’ section, I’ll select Direct PUT as the source. This means that applications can send data directly to the delivery stream using a Direct PUT operation.
Note: I’ll be using demo data from AWS for this tutorial, but the Direct PUT option lets you use data from various AWS services, agents, and open-source services. You can find more details on this support page.
- Here, we’ll use an Amazon S3 bucketas the destination.
- I’ll also choose ‘mydeliverystream’ as the Delivery stream name.
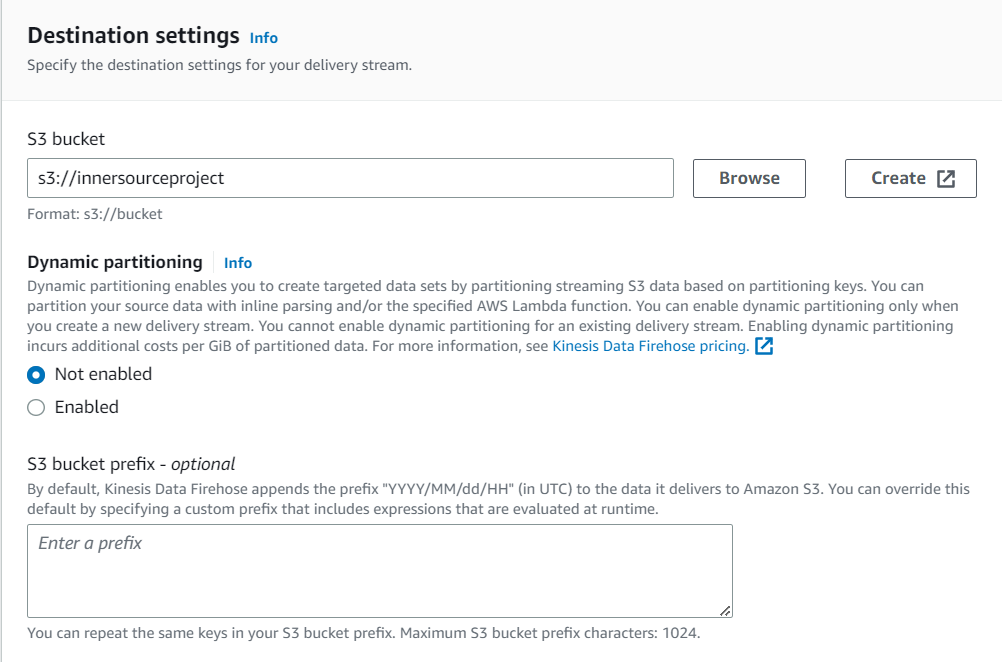
- You can ignore the Transform and convert options as they’re optional.
- In Destination settings, I’ll choose the AWS S3 bucket I want to use. You can leave Dynamic partitioning disabled as it’s an optional feature. Indicating an S3 bucket prefix and S3 bucket error output prefix is also optional.
- There are some additional settings for compression and encryption, but I didn’t use them for this demo. Click on Create delivery stream when you’re done.
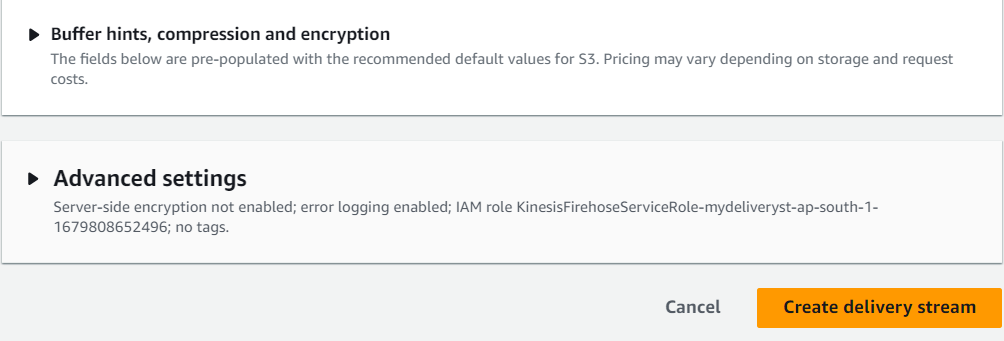
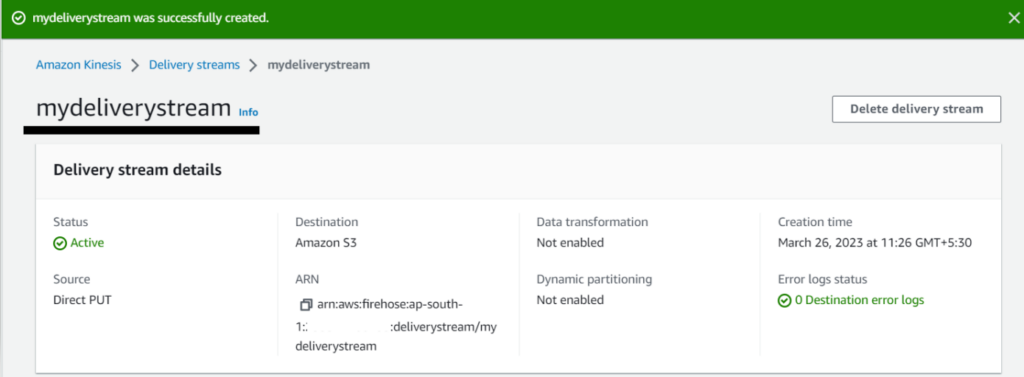
After our delivery stream was successfully created, we can now start sending data to our S3 bucket.
Sending data to a delivery stream
In this tutorial, I configured the destination for my delivery stream as an AWS S3 bucket. In the Delivery stream details, I can check if everything is working properly.
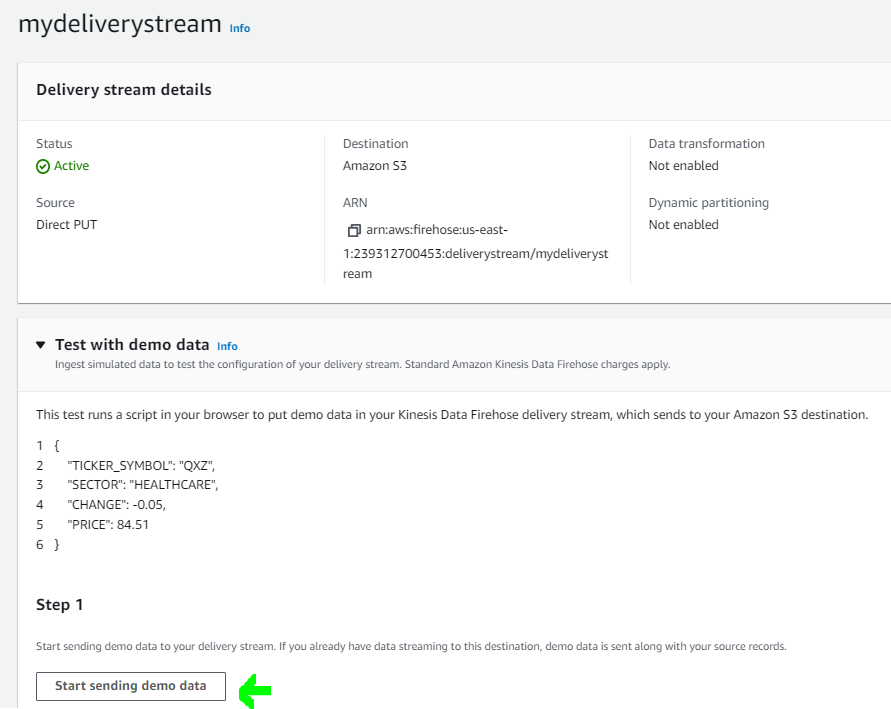
- In your delivery stream details, click on Start sending demo data.
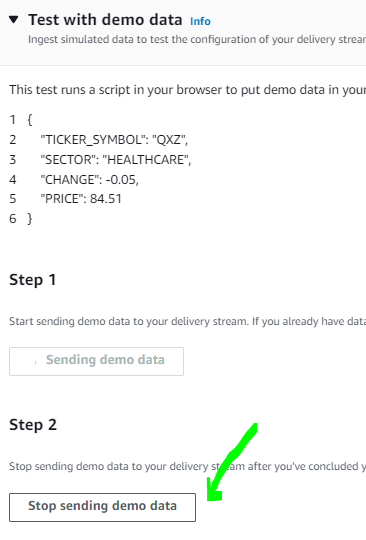
- Wait for a couple of minutes, then you can click on Stop sending demo data.
Now, I’ll open the AWS S3 bucket that I configured as a destination to see if the logs have been successfully sent. There is a folder named 2023 with the current year and subfolders in date and month format, and I’ll download and open the file named “mydeliverystream-1-2023-06-02-21-31-53-69ee0d29-aaaf-4dc9-9591-5f7738b6ee86stored” to check how the logs look like.
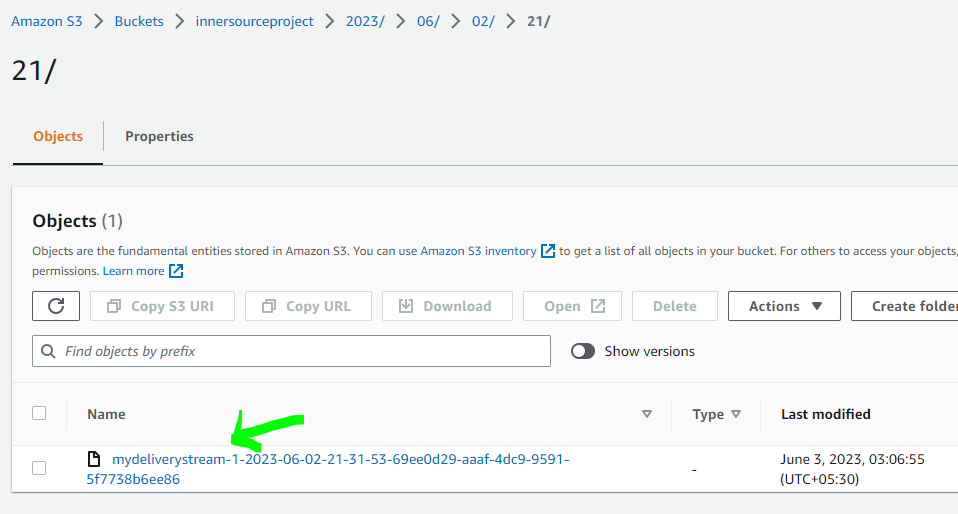
- As you can see, demo data was successfully pushed to my AWS S3 bucket using my Kinesis Data Firehose delivery stream.
Conclusion
In this article, I gave you an overview of how Amazon Kinesis Data Firehose works and I showed you how you can use this ETL platform for your own projects. This AWS service offers lots of benefits if you’re already using the AWS cloud, but it can also ingest and transform data from other sources. With its pay-as-you-go pricing model, you can easily get started without worrying about the required infrastructure.

Sagar is a DevOps consultant and the founder of automateinfra.com. Sagar brings DevOps technology expertise to Petri.com, writing about Terraform, AWS Cloud, Microsoft Azure, Ansible, Kubernetes, Docker, Jenkins, Linux, and Windows.