- Blog
- SQL Server
- Post
SQL Server Essentials: What Is a Relational Database?

SQL Server is a relational database. But what is a relational database exactly? Mike Otey, our resident SQL Server expert, explains in this article.
What is a relational database?
A relational database is a type of data storage mechanism that organizes data into tables where each table consists of rows and columns. It is typically used as backend data storage for programs and services.
The relational database model
The relational database model was initially defined by E.F Codd at IBM in 1970. The relational model uses structured data in multiple tables that are related to each other through common data elements in the table columns.
Relational database schema
A predefined schema defines the structure of the data and the relationships between different database entities. Tables have two different kinds of keys: primary and foreign:
| Primary key | Foreign key |
| Contains related data and are typically used for efficient data retrieval | Defines relationships between different tables |
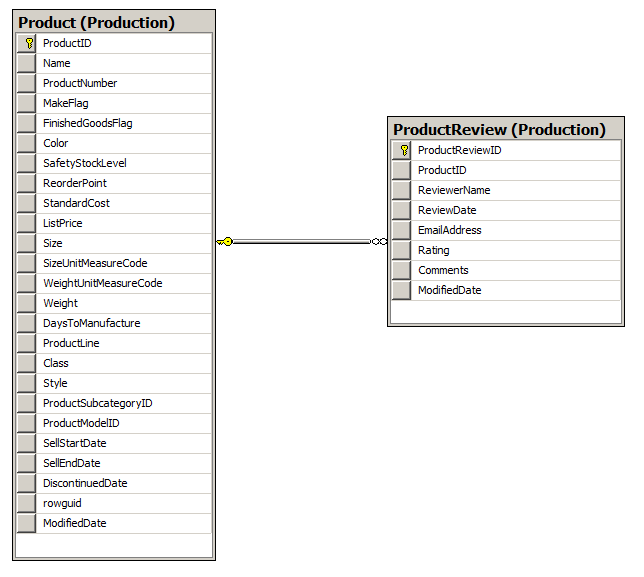
The image below shows a table for products, one for product reviews, and how a foreign key is used to pass product data into the reviews table.
What is Structured Query Language (SQL)?
Relational databases use SQL (Structured Query Language) to work with data in the relational data model. SQL is the standard programming language for interacting with all relational database management systems.
There are two types of SQL statements: DDL (Data Definition Language) and DML (Data Manipulation Language). Like you might guess DDL is used to create and manage database objects. While DML is used to retrieve data from the tables in a relational database.
What are the most common relational database systems?
Some of the most popular relational database management systems (RDBMS) include Microsoft SQL Server, Oracle, IBM DB2, MySQL and PostgreSQL. The most recent version of Microsoft SQL Server is 2022. In addition to on-premises database installations, there are cloud versions of most relational databases. For instance, Microsoft’s SQL Server cloud offering is Azure SQL.
Relational database components
Relational databases can seem complex but they all have some common attributes:
| Database | A relational database is essentially a collection of related tables that store data and other database objects. |
| Tables | A table is a structured set of data organized in rows and columns. Its purpose is to store and retrieve data. For example, a database might have tables for Customers, Orders, and Products. |
| Columns | Columns define the structure of a table by specifying the specific data types of each of the columns in the table. For example, a Customers table might have columns like CustomerID, FirstName, and LastName. |
| Rows | Rows are individual instances of data stored within a table. Each row represents a single entry in a table. For example, a row in a Customers table could represent a specific customer and it could have that customer’s Customer ID, first name, and last name. |
| Primary key | A primary key is a unique identifier for each row in a table. Typically, a primary key ensures that no two rows have the same identifier. It is used to reference specific rows using a unique Id. In the Customers table example, the CustomerID column might be an integer that acts as the primary key. |
| Foreign key | A foreign key is a column or group of columns that refers to the columns in another table. Foreign keys are used to establish relationships between tables. For example, an Orders table, you might have a CustomerID column as a foreign key. |
| Stored procedures | Stored procedures are batches of SQL code that can be saved and reused. You can pass parameters to a stored procedure allowing the stored procedure to change behavior based on the parameter values. |
| Constraints | Constraints are used to limit the type of data that can go into a table. They are used to ensure the consistency and reliability of the data in the table. If there is any difference between the constraint’s allowable values and the data to be added to a column the action is aborted. |
| Triggers | A trigger is a set of SQL statements that are automatically executed when a specific database action occurs. |
| Logins | A login is a security principal or an identity that can be authenticated to allow access to the database. Users need a login to connect to the database server. |
How is a relational database different from a NoSQL database?
NoSQL (Not Only SQL) databases are a newer category of databases that do not follow the relational model. These non-relational databases are a different type of database and they are better for unstructured data that doesn’t conform to a predefined data model and doesn’t fit into the relational database model.
Examples of unstructured data include:
- text
- emails
- photos
- videos
- web pages
- and very large amounts of data.
NoSQL databases are designed to handle large volumes of unstructured or semi-structured data and they often provide more flexibility and scalability than traditional relational databases. They are often used in applications where Big Data and horizontal scalability are a primary concern. Example of NoSQL databases include Redis, MongoDB, Apache Cassandra and Couchbase Server.
In the example I gave above of products and product reviews, if you end up with many related tables and foreign key relationships, you will need to join tables every time you query product information. You would also have to update indexes or foreign key columns to speed-up table joins, and this creates a lot of additional work and processing.
NoSQL databases have the advantage of allowing you to store related information as attributes of your primary table with related records, in this case, product reviews, in your primary table as an array or as sub objects.
Summary
In this article you learned about the basics of relational databases as well understanding what the components are that comprise them and how they are different from NoSQL databases.

Michael Otey is president of TECA, a technical content production, consulting and software development company in Portland, Ore. Michael is a former SQL Server MVP and was Senior Technical Director for Windows IT Pro and SQL Server Pro. He covers the...