Configured Exchange Server for High Availability? You Could Still Face an Extended Outage
Exchange Server Database Availability Groups don't always guarantee high availability.

High Availability (HA) was introduced in Exchange 2010 and since then has become the mainstay of message continuity in organizations. A high availability setup relies on Database Availability Groups (DAG) as a critical component to deploy a “highly available” messaging service and mailbox database across multiple Active Directory (AD) sites for resilience.
What is a Database Availability Group?
A DAG is a group of up to 16 mailbox servers. A DAG is configured with redundant copies of the mailbox databases to enable automatic recovery in case of a switchover (scheduled) or failover (unexpected) outage of the database, server, or datacenter.
Adding mailbox servers to a DAG
The DAG is created as an empty object in Active Directory. Mailbox servers are then added to the DAG object. Adding the first mailbox server automatically creates a dedicated failover cluster for the DAG. This failover cluster monitors the DAG’s crucial information, including:
- the database mount status
- replication status
- active/passive state, etc.
Mailbox servers that are subsequently added to the DAG are joined to the failover cluster.
Quorum model
The functioning state of a DAG, in case of failure of a member server, is determined by the quorum model of the failover cluster. Quorum serves as a file share witness to ensure that all, or a majority of cluster members, remain functional to serve “high availability” and “responsiveness”. You can also use a disk majority or now even cloud storage as a witness.
Outage Handling in high availability: Switchover and failover
There are two types of mechanisms for handling outage or downtime in a high availability Exchange Server organization:
- Switchover
- Failover
Switchover
Switchover comes into play when there is planned or scheduled downtime of the database, server, or datacenter, typically for maintenance, hardware upgrades, and windows updates. In a switchover, the administrator “manually” initiates the outage by using the Exchange Admin Center (EAC) or Exchange Management Shell. Switchover involves switching over of one or more active database copies to other mailbox server(s) in the DAG.
Failover
In contrast, Failover is an “automatic” response to an unexpected outage due to the failure of a database, server or datacenter, and it involves automated recovery by moving the active database copies to another mailbox server in the DAG, which was previously a passive server.
The Active Manager role
Switchover and failover mechanisms rely on Active Manager, a role that runs inside the Exchange Replication service on all mailbox servers in the DAG, to manage the switching of active databases to other servers.
Here is the process for switchover and failover, particularly in the case of a “database” outage.
Perform a database switchover
Here’s how an admin performs a database switchover in an Exchange Server DAG.
- The admin uses EAC or PowerShell to initiate switching the active mailbox database to another mailbox server in the DAG.

- The client relays a Remote Procedure Call (RPC) to the Replication service on a DAG member server that holds the Primary Active Manager (PAM*) role.
- The PAM updates the details of the currently active copy of the database in the cluster database.
- The PAM communicates with the Exchange Replication service on the target member that hosts the passive database copy to be switched into the active database copy.
- The Exchange Replication service on the target server queries the Replication services on all other member servers in the DAG to find out the best log source for the database copy.
- The current active database copy is dismounted and the Exchange Replication service on the target server copies the remaining logs.
- The Replication service on the target server initiates a database mount request, following which the Information Store service on the server replays the log files and mounts the database.
- The PAM updates the details of the database switchover in the cluster database.
- Any error codes are returned through the Replication service on target server via the Replication service on the PAM to the admin interface.
*PAM is the Active Manager role managing the active and passive database copies in a DAG. PAM role resides in the DAG member that owns the cluster quorum resource.
Database failover
In the case of a failover, here’s what happens:
- The Exchange Information Store service detects a database failure and records the event in the Windows Server crimson channel**.
- The Active Manager on the mailbox server, hosting the failed database, detects the failure events and initiates a request for the database copy status from the other servers in the DAG.
- The servers hosting the mailbox database copies, return the status, following which the PAM determines the best copy of the database and initiates the process to move the active copy.
- The PAM updates the new database mount location in the cluster database and sends a request to the Active Manager on the target server to assume the database master role.
- The Active Manager on the target server requests the Exchange Replication service to copy the latest logs from the preceding active server and sets the mountable flag for the database.
- The Exchange Replication service copies the logs from the server that was previously hosting the active copy.
- The Exchange Information Store service mounts the new active database copy.
**Crimson channel is a category of event logs in Windows Server that records the events associated with a single application or component, which in this case are High Availability and replication of mailbox databases.
When Exchange DAG switchover or failover goes wrong
There could be situations that might disrupt mailbox connectivity in a DAG HA setup. The following example illustrates:
Consider a DAG setup, comprising three member servers, namely MB01, MB02, and MB03, where each member server hosts a copy of three mailbox databases: DB 1, DB 2, and DB 3. The database copies are mirrored across each server.

Fig. 1: DAG with mirrored database copies
Note, this is a DAG comprising an odd number of members, so it is governed by the Node Majority Quorum model.
The DAG is seen running in a healthy state and is providing high availability. Next, the administrator needs to perform maintenance on MB02 and initiate a switchover. As a result, the active copy of DB 2 is moved from MB02 to MB01, and subsequently, MB02 goes offline. The DAG is still able to maintain high availability with MB01 and MB03; MB01 is now running two active database copies, those of DB 1 and DB 2.

Now, imagine that while MB02 is down for maintenance, MB01 faces a sudden hardware failure and crashes. What happens next is the loss of cluster quorum, so the DAG will not be able to initiate a failover and undergoes total failure, resulting in the databases dismounting. This happens by design as there is only one server left and one node to vote, so as a failsafe, the cluster is shutdown.

This situation leads to an extended outage until the failed member server is recovered to reinstate the quorum and restore the DAG. It requires manual intervention of the administrator to recover the server.
In the meanwhile, and until the HA setup is restored, mailbox connectivity in the organization will remain hampered, despite “availability” of the mailbox database copies. However, mere availability will not guarantee restoration of the “latest mailboxes”, given the fact that MB01 – the server that crashed – was hosting the active copies of DB 1 and DB 2. So, there is a significant chance that the database copies hosted on MB01 are in a dirty state.
Check the state of the database and restore it to a consistent state
Follow these steps to check the state of the database and restore it to a consistent state:
Step 1: Ascertain the Database State by Using ESEUTIL
You can check the state of the database files by using ESEUTIL /MH cmdlet to read the header of the database in offline mode, as follows:
eseutil /mh ”c:\DB 1.edb”The above cmdlet checks the state of the database file, named DB 1.edb. It returns the database state as “Dirty Shutdown” and displays the missing log file range in the Log Required section.
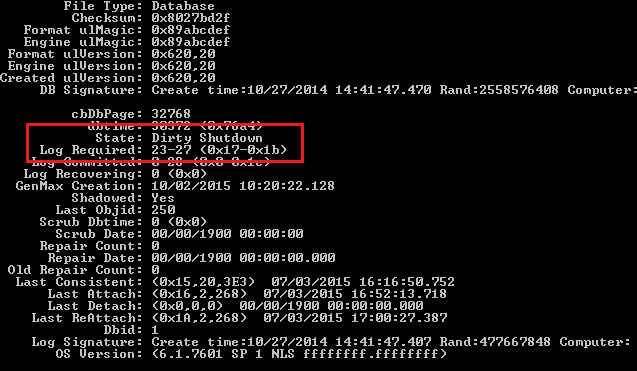
Step 2: Attempt Soft Recovery Using ESEUTIL
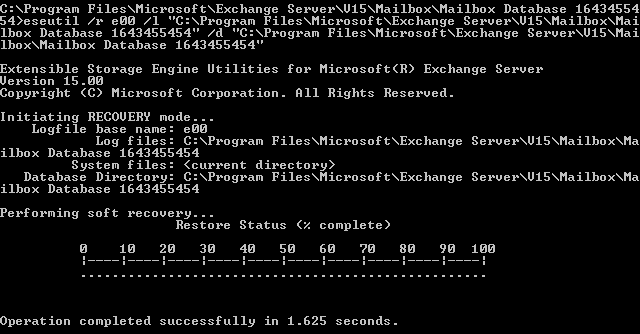
Use the ESEUTIL /R cmdlet to replay the transaction logs and restore the database to a consistent state, which is also known as soft repair or recovery. The following is the syntax of ESEUTIL /R cmdlet, further illustrated with an example:
ESEUTIL /r <log_prefix> /l <path_to_the_folder_with_log_files> /d <path_to_the_folder_with_the_database>Example:
ESEUTIL /r E00 /l “C:\Program Files\Microsoft\Exchange Server\V15\MB01\DB 1” /d “C:\Program Files\Microsoft\Exchange Server\V15\MB01\DB 1”This example illustrates the use of the ESEUTIL /R cmdlet to perform soft recovery of database, named DB 1.
Next, recheck the database state by using ESEUTIL /MH cmdlet.
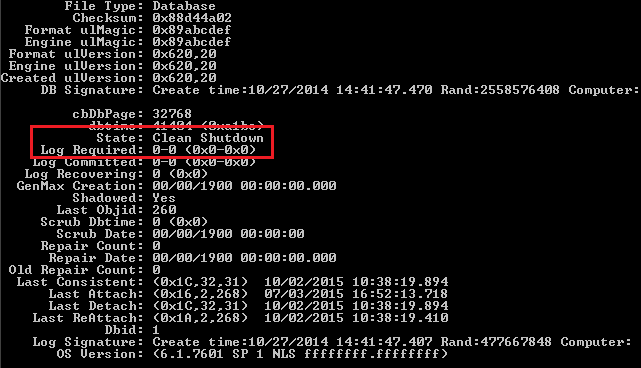
By using the ESEUTIL commands, you should be able to restore the database to a clean shutdown state and mount it successfully, reinstating access to the latest copies of users’ mailboxes.
What happens if the soft repair method doesn’t work and the database is still found in the Dirty Shutdown state after running the ESEUTIL /MH cmdlet?
You can attempt a hard recovery by using ESEUTIL /P cmdlet, but be aware that the hard recovery method involves “removal” of data to attain database consistency, and therefore it results in data loss. So, it must be used only when there is no other option. In fact, EseUtil itself will prompt you to accept the data loss.
Hard recovery is not a 100% guaranteed solution and you must also consider that Microsoft adds hard-coded information in the database if hard recovery is used. If you have a support agreement with Microsoft and you ask them for assistance after you run a hard recovery, they will not support you, as it’s a breach of the support agreement.
As an alternative, and a more successful method to recover the databases with no complications and with ease, use a third-party tool to repair corrupted Exchange Server databases and restore Exchange services with the least impact to business and without data loss.
Summary
High availability is undoubtedly the preferred architecture in Exchange organizations worldwide, as it ensures business continuity. Based on DAGs, HA can be extended beyond a single datacenter to multiple AD sites for attaining site resilience, which is a dream setup for any Exchange administrator. But, like any other system, there are un-factored failover scenarios that could lead to extended disruptions, which in the case of Exchange Server, could mean downtime for email and even data loss.
For instance, incidents like server crashes can lead to complete failure of DAGs and corrupt the database copies, putting administrators in a tight spot. In this case, apart from using ESEUTIL, there’s not much that can reliably fix the database corruption and mount the database.
Also, data loss is an added risk, if hard recovery comes into play. You must also factor in the downtime, administrative effort, and resources needed to restore the services. So, owning a third-party Exchange database recovery tool can be a smart move for handling such situations, given the fact that database corruption can happen anytime and for reasons beyond your control.
Bharat Bhushan is an experienced technical Marketer at Stellar Data Recovery. His expertise is in data care. He is skilled in Microsoft Exchange, MSSQL troubleshooting and data warehousing. He is a Management Post Graduate with a strong understanding...