




Hyper-V is a very resilient hypervisor, designed to protect your workloads from corruption. Corruption can come in many forms. Maybe Hyper-V pauses your virtual machines because a Cluster Shared Volume is full and it’s protecting your business or customer from dynamic virtual hard disks trying to consume space that is no longer there. Or maybe your host has failing memory DIMMS and Hyper-V is aware of this and is ensuring that your virtual machines will not consume that RAM. The latter is where Hyper-V is using hardware error detection to protect you from your hardware. I recently encountered the latter in person, and here’s what I found.
What is WHEA?
WHEA stands for Windows Hardware Error Architecture. MSDN describes WHEA as a mechanism where Windows and the firmware of the underlying hardware work together to detect hardware issues and deal with them.
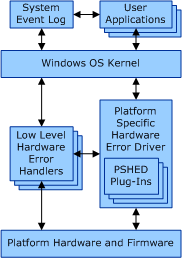
Since Windows Vista, Windows maintains a list of discoverable hardware error sources. For each source that is discovered on a physical machine, Windows maintains a low-level hardware error handler (LLHEH). When a hardware error is reported to Windows, the LLHEH is the first piece of code to run in response. Microsoft places each LLHEH in the appropriate part of the operating system to deal with the issues of the related error source.
When an LLHEH runs, it will:
- Acknowledge the error
- Capture information related to the error
- Report the error condition to the operating system
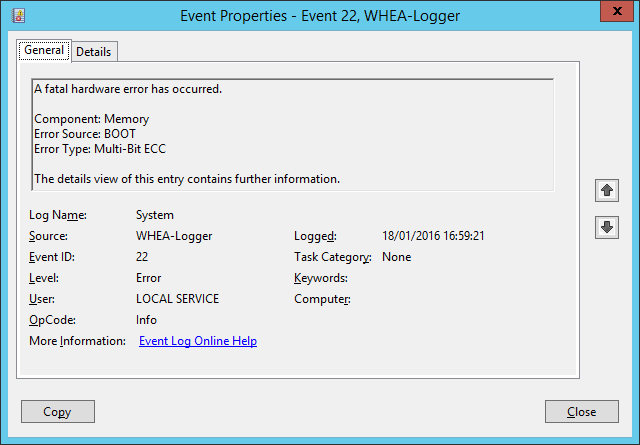
I recently saw the following WHEA error in the System Log of a Hyper-V host:
WHEA and Hyper-V
Traditionally, the most precious resource on a virtualization host has been RAM. Virtualization has given us tools to optimize how we use RAM to squeeze more virtual machines onto our host hardware. And over time, hosts have grown. Gone are the days of hosts with 64 GB of RAM being a sweet spot. These days, the smallest host my company sells has 128 GB RAM, and we’re more likely to see 256 GB or 512 GB RAM hosts, thanks to the ever falling price of DIMMs. But as we add more memory chips into hosts, we are creating conditions where there is a higher probability of chip degradation.
Let me be clear about that language; I said degradation, not failure. An outright failure of a DIMM is easily handled — it’s dead and unusable. But what happens if part of a DIMM becomes faulty and untrustworthy without triggering an alarm?
Hyper-V is made aware of the fault thanks to WHEA. And Hyper-V is intelligent enough to protect you from this failure by isolating the affected memory and ensuring that virtual machines don’t use it anymore.
What happened with the host that created the above alert? I knew to look for errors because there was a report of an alert on the front console of the server. I logged into the remote management of the physical server and the current status was healthy; there were no apparent hardware failures. But I had a WHEA error indicating that there was a memory degradation. I browsed into the logs of the server’s remote management and found a hardware error report to prove that there was a dodgy DIMM.

Armed with that information, I’ve been able to request a memory swap out to prevent any further issues with this host … and it was great to know that Windows and Hyper-V had my back.