



Azure Virtual Machines SLA: A Primer
A huge worry that people have with placing virtual machines in the cloud is that these machines suffer some form of outage and leave businesses in the lurch. We have a lot of control over uptime when we work on-premises, where we can deploy virtualization clusters to get highly available virtual machines, and we can deploy load balancing or failover clustering in conjunction with anti-affinity to achieve highly available services.
We have no control over the infrastructure when we’re working in the cloud, so we relying on the best efforts of the hosting company to keep our machines online. These best efforts are governed by a service level agreement (SLA). In this article, I’ll cover what this SLA is for virtual machines that are running in Azure, and discuss what you need to do to meet the requirements to become eligible for this SLA.
Fault Domains and Availability Sets
Azure is made up of maintenance or fault domains. Each of these domains is made up of a group of hosts that are logically and physically grouped. This grouping can affect virtual machines on these hosts in a couple of ways:
- Outage: If there is a network access issue or a power supply issue, it’s possible that the entire maintenance/fault domain is affected. However, the fault is usually contained within the boundary, unless it’s a data center-wide, Azure region-wide, or Azure-global issue.
- Maintenance: Procedures within Azure dictate that updates or repairs are done on one maintenance/fault domain at a time. These means that only a single maintenance/fault domain will be offline at a time, and if there’s an upgrade-related issue, it should be limited to just those maintenance/fault domains that have been updated.
What does this mean in real-world terms? Say, for example, you deployed a single virtual machine as a file server in Azure North Europe. When Microsoft schedules an update, you will receive an email that reads something like this, with about one weeks’ notice:
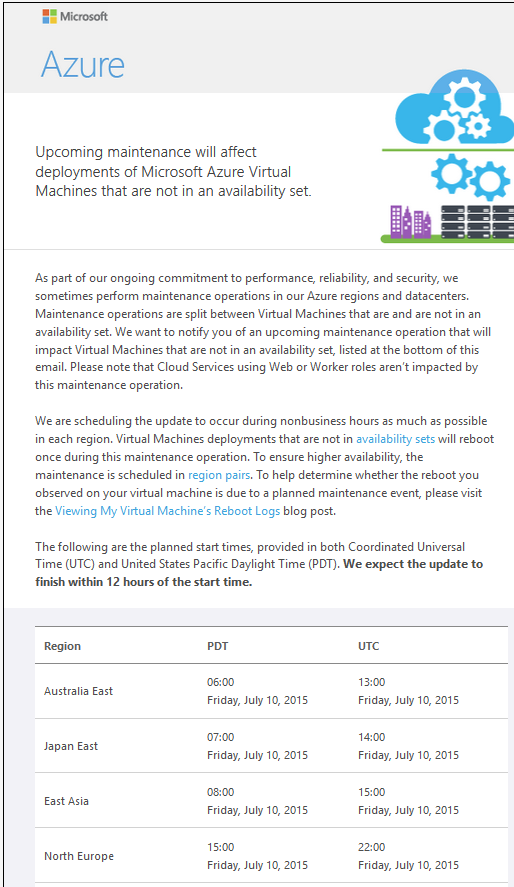
What we’re told is that any virtual machine that’s not in an availability set will be rebooted once during a maintenance period. A reboot doesn’t sound too bad, right? However, Azure virtual machines are very slow at rebooting, and what happens if there’s an issue? And that outage could be anytime between 3 pm and 10 pm. So my file server might go offline for 10 minutes during the end of the work day when employees are trying to close up business before the weekend.
Doesn’t this breach the SLA? You might think so, but that’s not the case.
Why is there no Live Migration before host maintenance like we can implement with Hyper-V’s Failover Clustering Cluster Aware Updating (CAU)? Believe it or not, Azure doesn’t perform Live Migration. In Microsoft’s opinion, no single virtual machine should be so important when you’re working in Azure; it’s all a part of Jeffrey Snover’s outlook on “treating your servers like cattle, not as pets.” This can prove to be incompatible with some workloads, as you will find out.
The SLA for Azure Virtual Machines
Microsoft states that the SLA for virtual machines that are running in Azure is 99.95% if those virtual machines are in an availability set. The reason for this is that fault domains are … designed to fail. Microsoft Azure is cloud scale; when you work at this scale, you don’t do all the usual fault tolerance stuff that you would do with a virtualization cluster in even a large corporation’s data center.
Azure is built big and cheap, with fault tolerance being provided via deploying services into more than one fault domain — the assumption is that any service that you deploy in Azure will require two or more instances per tier, and therefore be spread across multiple fault domains. We can ensure that each tier of the service is in a different fault domain by adding the machines to a common availability set — what you might know as anti-affinity from vSphere or Hyper-V. With this configuration enabled, Microsoft can limit planned or unplanned outages to a single fault domain, and leave your service operational.
Availability sets really do require some level of high availability at the service layer. Think about it; work is being processed on VM1 in one fault domain and VM2 in another fault domain. If VM1 fails, then all requests are redirected somehow to VM2, and the service running on these machines must be designed to handle this.
Highly-Available Cloud Services
You cannot just stick any machine into an availability set and assume that things will be good. First, you need at least two machines in an availability set for it to be valid. Second, these machines must be running a service that provides high availability at the service layer. We can do this in a few ways including:
- Load balancing: You can implement internal or external load balancing at the IP layer to spread traffic across multiple virtual machines in different fault domains. An extension of this is to use Traffic Manager to spread traffic across multiple Azure regions (or further afield if you do a little research on external endpoints).
- Failover clustering: You enable clustering in the guest OS to make the guest service highly available. This one is tricky — more on this later in the article.
- Born-in-the-cloud application: The developers of the application that’s running the virtual machines understood Azure, and built fault tolerance in at the application layer, not requiring the Azure fabric to provide HA features. Not too many legacy services fall into this area.
A Real-World Example
If I have a web farm, I could deploy two or more web servers in availability and load balanced sets. Any incoming HTTP/S traffic would be balanced across each web server, and the loss of a single stateless machine would not bring the service offline.
Application services could be custom developed, maybe with a message queue transaction system, to handle the processing of transactions that are passed in via the web servers. This application is born-in-the-cloud, so the developers have handles HA at the application layer. I can simply deploy the application servers in an availability set and meet the requirements of the Microsoft SLA.
If I have domain controllers, then these can be Basic A-series virtual machines in an availability set.
But what about the file server that I mentioned before? A single file server cannot be added to an availability set. I need to file servers. If the shared content is user-accessed, then I cannot use DFS-R; it does not have distributed locks and last writes win. What you need is a highly available file server based on Windows Server Failover Clustering … and there’s a gotcha with that. Failover Clustering of this kind of data service requires shared storage. In Hyper-V, I could deploy a Shared VHDX file and use that as the shared SAS storage between my virtual nodes. Azure doesn’t offer Shared VHDX. I also cannot use Azure Files. So the solution that I have to deploy is based on third-party volume replication; this solution will replicate data disks between two Azure virtual machines and simulate cluster-supported storage. I can then place file shares onto this replicated volume to create a HA file server, where Windows Server 2016 Storage Replica should make this much easier.
High Availability with Azure
Some hosting companies might offer you five nines (99.999%) or even an unachievable 100% SLA on virtual machines. Remember that they do this at a premium. Azure offers you more affordable scalability, but you must understand that you have to deploy virtual machines into availability sets to meet the requirements for the 99.95% SLA that Microsoft offers. You cannot assume that your service will suit availability sets, so understand the service and how it can be made highly available at the guest layer.