



The Microsoft Azure Outage: Why It Happened
I woke up yesterday morning (Wednesday, November 19th) to find my Twitter feed filled with angry tweets about Azure issues. Customers at work were suffering outages. Something had gone wrong in Microsoft Azure and it was taking some time to resolve.
What Happened?
At around 00:52 UTC (19:52 PST or 01:52 CET) a number of services started to suffer performance issues and outages, including:
- Storage
- Virtual machines
- Visual Studio Online
- Websites
- Search
- And much more
The issue appeared to affect all regions, if not most, with the issues being slightly different in each region – Kurt Mackie of Redmond Magazine has more details. This was a widespread failure in Azure that affected customers for several hours. Over 24 hours later (when I wrote this post), some customers in the West Europe (Amsterdam) region are still having issues with virtual machines.
The Cause
Microsoft explained the cause of the issues in a post on the Azure blog, authored by Jason Zander, Corporate Vice President of Microsoft Azure. A performance update was deployed to Azure Storage. This update had been previously tested in “a subset of our customer-facing storage service for Azure Tables”, according to Zander. This “flight” in Azure Tables proved that the update improved performance. Unfortunately for customers of Microsoft Azure, the testing practices of Microsoft that continue to hurt on-premises Server products, finally caught up with Microsoft’s public cloud.
An issue that went undetected in the Azure Tables flight arose on Tuesday night/Wednesday morning after the update was applied globally to Azure Storage. The storage blog front ends (see below) went into an infinite loop and were unable to service additional requests. This caused other services, that depended on Azure Storage, to suffer issues. This explains the wide breadth of the issue; services such as virtual machines and websites all use Azure Storage.
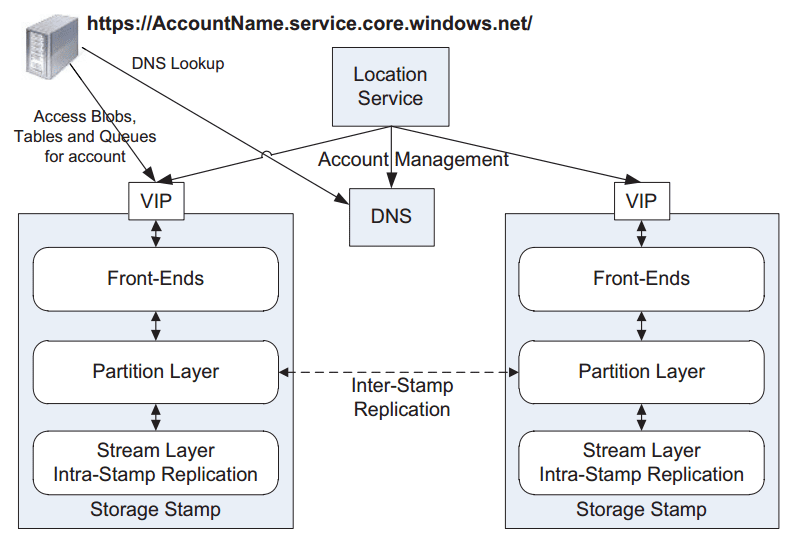
Microsoft took action straight away by rolling back the updates, but the front ends needed to be restarted. It took some time for services to recover, and some customers continued to have issues. According to Microsoft’s own update, the issue started at 00:51 UTC and wasn’t resolved until 11:45 UTC. Nearly 11 hours of an outage, across the world – Ouch!
The Failures
The first and core issue at hand is that Microsoft deployed an inadequately tested update globally to all elements of Azure Storage. Customers of Windows Server and System Center have seen how bad updates from this larger product group have been. Some, such as myself, have taken a stance that we should no longer be Microsoft’s testing canaries, and we should delay deploying updates for 4 weeks. With this approach, others (the canaries in the mine) fall victim to the issues, we let Microsoft fix them, and then we get/approve the fixed updates for deployment several weeks later, without unwanted outages and messy rollbacks.
Microsoft tested the performance update on a different storage system. Maybe the architecture is the same, but maybe it isn’t (we’ll never know). But it sure sounds like the demands on the systems are different. It appears that the infinite loop issue with Azure Storage kicked in pretty quickly.
Many of us who run larger systems keep a test rig that is a clone of our production network. This allows us to test updates before deploying them. And then we have a pilot collection of machines (how I would implement it using Microsoft System Center Configuration Manager) that we would approve first before approving the update(s) to the entire network. This two-stage process allows us to validate patches on identical systems and on real workloads without risking the entire basket full of eggs. It appears, that Microsoft does not do this. Hmm – I’ve always wondered if developers should be running IT systems? IT pros would know not to do this sort of thing.
The second mistake was poor communications. A long time ago, I started to work for a hosting company. One week into the job, an electrician made a boo-boo and he brought down one third of the Internet hosting capacity of Ireland. The outage took an hour to fix but it led to repercussions that took over 12 hours to sort out. Obviously there was anger … but my bosses had figured out that clear communications could temper that anger. And they also knew that those communications should eb hosted on other service providers’ systems to avoid a chicken and egg scenario (where you cannot explain an outage because the outage has brought down your digital communications). Most customers understand that IT is complex and has issues. If you keep those customers informed during the process then most of them might still be unhappy about the issue, but appreciate that you are doing your best.
At my place of work, we had calls from customers that didn’t understand what was happening. Virtual machines had crashed and wouldn’t start. They hadn’t heard from Microsoft. Microsoft’s Azure Status site was claiming that things were just dandy during the first three hours of the issue; it was affected by the issue too! Microsoft did tweet about it and used other social media … but that’s hardly alerting, is it? Microsoft has:
- The ability to monitor systems
- An email system (Exchange online)
- The email address of every subscriber owner and delegate administrator
It shouldn’t take too much to connect A, B, and C and tell customers that they have an issue. If they need inspiration, there is a blog post called Monitoring Azure Services and External Systems with Azure Automation that was posted on the Azure Blog on Monday, November 17th. And all communication systems, be they portals, social media, or messaging, should have no dependencies on Azure services.
I am still an advocate of Azure for hybrid scenarios. I am unhappy that there was an issue. But I understand that stuff happens – any IT pro that hasn’t been there has just started in the job! I just wish that Microsoft had better testing/deployment plans and improved their communications.