



How the Microsoft 365 Substrate Powers Intelligent Search
Refreshing the Substrate
Last year, I wrote about the Office 365 substrate, a little understood but critical component of how Microsoft is developing their cloud services. That article followed a talk by Microsoft Fellow Jeffrey Snover at the Ignite 2019 conference. Now boasting the title of CTO for Modern Workforce Transformation, Snover recently explored the same topic at the Microsoft Higher Education conference. His remarks helped me understand some additional aspects about the Microsoft 365 substrate. Perhaps these notes will help others get to grips with this important topic.
The Substrate Holds Everything
The basic thing to understand about the substrate is that every piece of data in an Office 365 tenant is stored in it. The data is either native to the substrate or a digital twin replicated from another store, like the Teams message store in Azure Cosmos DB or SharePoint documents from Azure SQL. When items come from another store, they are often a subset of the original which contain just the information needed to support functions like search and information protection. If you go poking into the innards of Exchange Online mailboxes with a program like MFCMAPI, you can see some of this data in hidden folders. For instance, the GraphWorkingSet folder holds subset items with pointers in properties like FileId and GraphNodeId. The result is that the substrate is a single repository for everything in a tenant. Snover calls the substrate a planetary scale data system. Its physical implementation is in Exchange Online storage and is protected by four database copies in distributed datacenters.
Leveraging the Substrate for Search
Because the substrate holds all the data for a tenant, services like Search can use the substrate as a natural source for information. And unlike old-style search based purely on indexes, more intelligent methods can be used to explore and connect data to deliver quality results which are highly relevant to the requestor. For example, if someone is looking for a document, they can find it in multiple ways from a simple search to navigating to the right file through organizational objects like a department, meeting, or anything else which might be associated with the document.
Microsoft Search in Bing is a good example of making substrate data available to end users. If you configure the Search and Intelligence settings in the Microsoft 365 admin center to allow tenant users to see Microsoft Search results in Bing, they can go to Bing.com or use the address bar in a browser to see results from work sources along with those from the web. Work sources mean files from SharePoint Online and OneDrive for Business, conversations from Yammer and Teams, Groups and distribution lists, and the ubiquitous people card (Figure 1). Although results don’t include messages from Exchange Online mailboxes, it’s clear that the substrate makes it possible to bring these results together and present them as a collective set.
The ability of Search to generate relevant results is enhanced by the signals gathered from user activity across the substrate, such as reading a message, replying to a Teams conversation, or creating a meeting. These signals are stored in the Microsoft Graph, which is another part of the Substrate (Figure 2). Applications like those built on Project Cortex can use this information to create “synthetic nodes” based on artificial intelligence analysis of common objects like projects, tasks, and acronyms. Instead of being created to match some arbitrary view how an organization works, these nodes are based on what is used in an organization. In turn, because the nodes are accurate representations of real data, they help search deliver better results and navigation of those results be more productive.
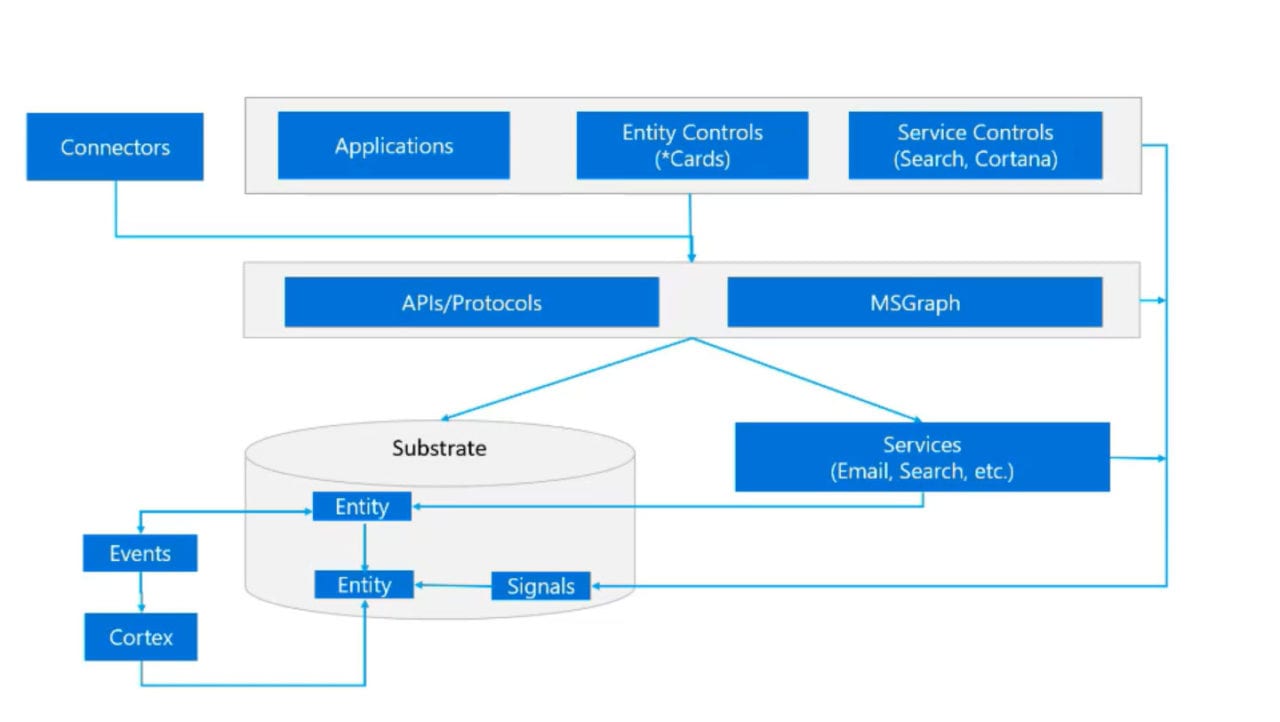
Graph Transversal
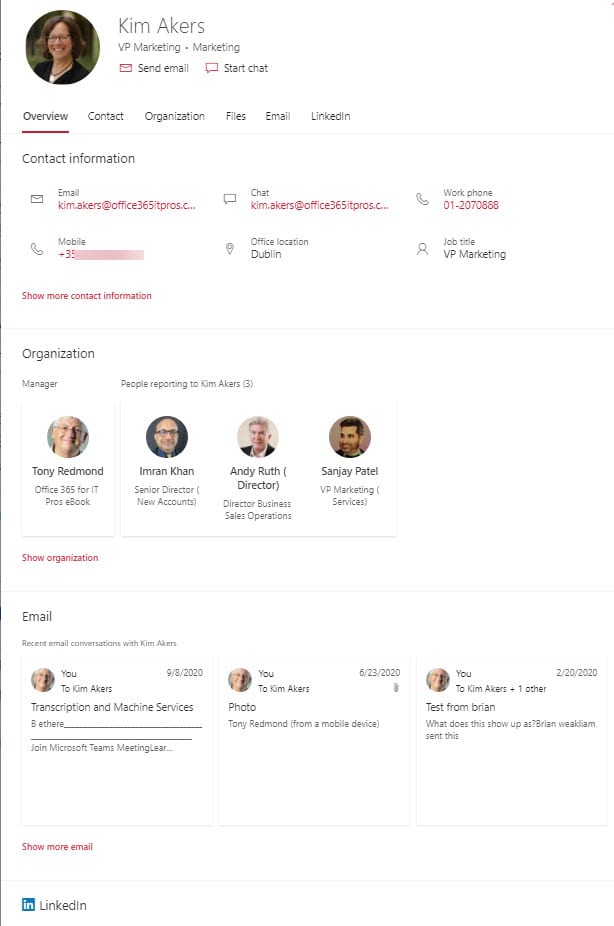
Snover made the point that the value of the data held in the Graph is enhanced by “graph transversal,” or the ability to move from one Graph source to another to build a full picture of what a user might want to find. For instance, when someone views details of another user through the People Card, they can see basic information about their account (name, email address, phone numbers, etc.) plus organizational information from Azure AD (Figure 3).
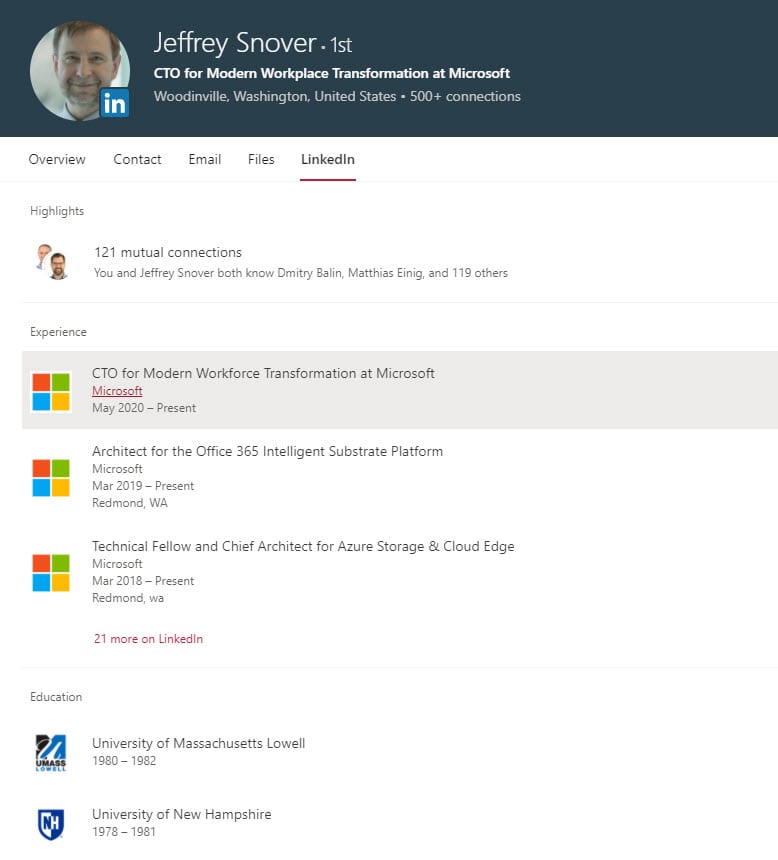
If someone’s account is connected to a LinkedIn account, the user’s full career information is available from the LinkedIn graph (Figure 4). This is a good example of Graph transversal.
Developing Against the Substrate
To make it easier for developers to build high-quality applications leveraging the substrate, Microsoft enables developer access to substrate date through well-defined APIs (the Graph endpoints to resources such as Outlook, Azure AD, Planner, and Teams) along with traditional APIs, including PowerShell. In addition, Microsoft has developed several entity controls or cards to make it easy for developers to perform common tasks. The people card mentioned above is one example.
Snover focused on the people picker as an example of the power of a well-designed entity control. The people picker is used in Outlook, OWA, Teams, Word, and any other place within Microsoft 365 where someone needs to send something to another person. Behind the scenes, artificial intelligence determines the most likely set of people the user might want to interact with and suggests those names. If the user selects someone else, AI learns from the decision and adds that person to its list.
Figure 5 shows the people picker in action in Outlook for Windows. Typing Jeff in the TO: box causes the picker to generate a list of the most appropriate matches divided into recent contacts (people whom I have recently communicated with) and other suggestions. Interestingly, the set suggested are all people who participated in a Teams meeting in another tenant. Their presence in the chat history for that meeting is sufficient for them to become a candidate for suggestion. My tenant is small, so the list of recent people will be longer in larger tenants, but it’s enough to make the point.
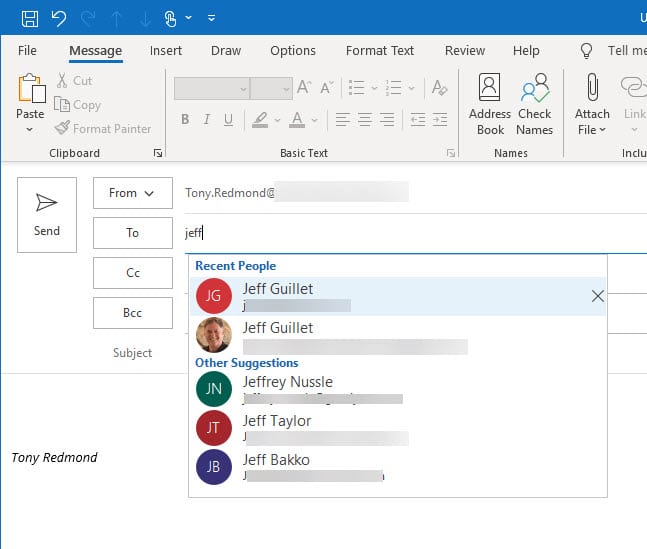
Controls like the people picker take on the UI characteristics of the application which use them. For instance, the appearance of the picker is different in OWA than it is in Outlook, and it differs again in Teams. However, the point is that the same code and artificial intelligence powers the picker no matter where it is used.
Big Important Stuff
It’s obvious that Microsoft has made a very big bet on the substrate. Its central role and importance are obvious, as is the value of having a common repository for services to base their processing upon. Like many of its internal processes and technologies, Microsoft doesn’t talk about the substrate a lot, and details are limited to what can be gleaned from sessions at Ignite and other conferences. In some respects that’s a pity because this is interesting and impressive technology operating at massive scale.