



How Many CSVs Should a Scale-Out File Server Have?
I’m often asked the same question about how many virtual disks or cluster shared volumes my shared-JBOD Scale-Out File Server (SOFS) should have. I’ll answer this question in detail and provide a technical explanation for the logic in this post. Note that the scenario that I am discussing uses Windows Server 2012 R2 and a shared JBOD SOFS design with Storage Spaces.
- Related: What is Microsoft’s Storage Spaces?
How Hyper-V Hosts Connect to a Scale-Out File Server
First, we need to understand how a Hyper-V host connects to the CSVs of a SOFS cluster via SMB 3.0. Let’s start with a simple SOFS design that has two nodes, one JBOD, and one mirrored virtual disk configured as a CSV.
The CSV is owned by one of the SOFS nodes, which is represented by SOFS Node 1 in the image below. Any writes to the mirrored virtual disk are done by this owner node. If the other node, SOFS Node 2, needs to perform IOs with this CSV, then they must be proxied by the other node via redirected IO across the SOFS cluster’s networks.
A correctly configured SOFS cluster will be set up as follows:
- DNS servers will be entered in the IPv4 configuration of the storage NICs
- Client and cluster communications will be enabled on the cluster networks that use the storage NICs
These two configurations cause the SOFS to register a record in DNS for its management of the IP address and the addresses of the storage networks.
In this example, let’s assume that a Hyper-V host is powering up for the first time and wants to connect to a share on the SOFS. This share is stored on CSV1, which is owned by SOFS Node 1.
When a Hyper-V host or any SOFS-compatible service, such as SQL Server, connects to a share on the SOFS, then it will perform a DNS lookup of the SOFS’s FQDN. DNS will return the IP addresses of the management NIC and the storage networks.
If you have designed or configured SMB 3.0 Multichannel correctly on your hosts, then the host will randomly select one of the SOFS cluster’s nodes to connect to. In our case, the Hyper-V host randomly selects SOFS Node 2. The host connects to SOFS Node 2, but SOFS Node 2 does not own the CSV that the share is on and has to use redirected IO across the SOFS cluster’s networks to access the virtual machine files. Traffic will initially flow as follows:
- Hyper-V host to SOFS Node 2 via SMB 3.0
- SOFS Node 2 to SOFS Node 1 via redirected IO (SMB 3.0)
- SOFS Node 1 to the JBOD via SAS
Don’t panic! SMB 3.0 will redirect the Hyper-V host to the owner of the CSV. This means that the Hyper-V host will transparently redirect to SOFS Node 1, the owner of the CSV, to give us direct IO:
- Hyper-V host to SOFS Node 1 via SMB 3.0
- SOFS Node 1 to the JBOD via SAS
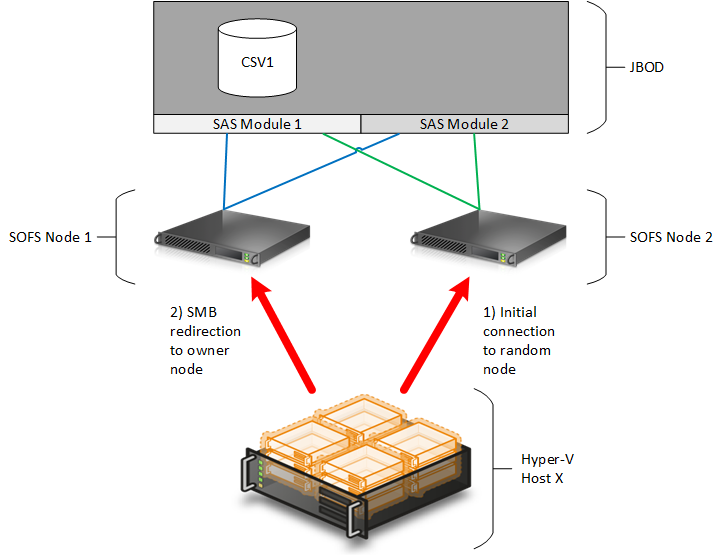
There is a problem now: SOFS Node 2 is not handling any traffic. Yes, it is there to accept failover of the CSV and to perform transparent failover of SMB 3.0 traffic, but its potential is wasted.
Best Practice for CSVs in Scale-Out File Server
We typically recommend that a SOFS has at least one CSV per server/node in the SOFS cluster, with each CSV requiring a Storage Spaces virtual disk. If I have two servers or nodes in the SOFS, then I have at least two CSVs. If there will be four servers, then there will be at least four CSVs. Why is this the rule of thumb?
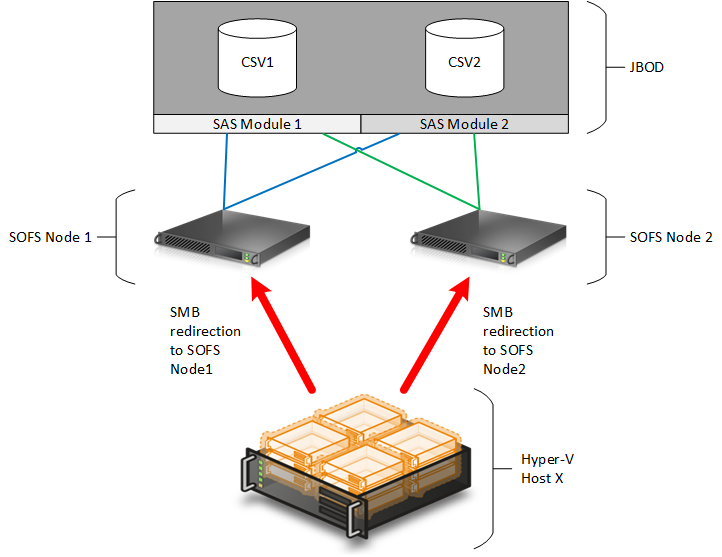
When you have more than one CSV in Windows Server 2012 R2, failover clustering will balance the ownership of those CSVs across nodes in the cluster. So, if we take our example SOFS and add a second CSV called CSV2, then we will find that CSV1 and CSV2 are each owned by one of the nodes in the SOFS cluster. For our example, let’s assume that CSV1 is owned by SOFS Node 1 and CSV2 is owned by SOFS Node 2.
A combination of features will balance SMB 3.0 traffic from our host via both SOFS nodes:
- When the host connects to CSV1, it will use the random DNS-based process to select one node to make an initial connection. If the host selects SOFS Node 2, then SMB redirection will send it over to SOFS Node 1 after a brief moment of redirected IO within the SOFS cluster. Now the host has direct IO to CSV1 via SMB 3.0 and SAS through SOFS Node 1.
- When the host connects to CSV2, it will use the random DNS-based process to select one node to make an initial connection. If the host selects SOFS Node 1, then SMB redirection will send it over to SOFS Node 2 after a brief moment of redirected IO within the SOFS cluster. Now the host has direct IO to CSV3 via SMB 3.0 and SAS through SOFS Node 2.
The host will use SMB 3.0 to connect to both SOFS Node 1 and SOFS Node 2 to get direct IO to the relevant CSV in the SOFS cluster’s shared JBOD.
How Many Shares per CSV?
While we’re talking about best practices, we should finish up by talking about how many shares you should have per CSV. As you will soon see, this has an impact on the number of CSVs in your SOFS.
I used to think that we should keep the number of CSVs low by creating a share for each required host, cluster, or set of hosts and clusters with a common domain of Live Migration, which is the permissions of the SOFS share control that hosts can access and live migrate a virtual machine. But I was wrong, the best practice is actually to have one share per CSV. You will find this best practice implemented by System Center Virtual Machine Manager, which will provision shares for you in a managed SOFS. This approach does keep things simple in terms of tier management, capacity planning, and documentation.
When combined with CSV ownership balancing and SMB redirected IO, the one share per CSV model will offer you best possible performance across your storage and SAS networks.