



Guide: Getting Started with SharePoint Syntex – Problem, Solution, and Methodology
Microsoft announced SharePoint Syntex at Ignite 2020 as part of Project Cortex. In Microsoft’s own words, SharePoint Syntex transforms your content into knowledge using Advanced AI and machine teaching. Sounds great right? But what does this actually mean to SharePoint users? What real-world problems does SharePoint Syntex solve for Microsoft 365 customers, how do you license and configure it, and most importantly, what does it cost you to implement?
In this, the first in a series of posts on SharePoint Syntex, we explain what SharePoint Syntex does, introduce the two models which SharePoint Syntex provides, and examine how and when to apply SharePoint Syntex models to content in SharePoint Online document libraries. Further posts will cover implementing SharePoint Syntex models, and my tips and best practices for getting the most out of SharePoint Syntex.
The Problem
So, to the important question. What problems are we looking to solve by using SharePoint Syntex? Well, let’s take the example of an Engineering company that manufactures engine parts. They already use SharePoint Online to store and access company documents and have a good structure of Communication Sites and Team Sites for departmental functions all tied together with Hub Site navigation.
The Engineering team has a SharePoint Online Team site to store Scopes of work that they produce for customers (Figure 1).
Similarly, the Finance team has a SharePoint Online Team site to store Invoices (Figure 2).
Just looking at each of these document libraries tells us little about the content, however, other than the names of the document libraries and some potentially obvious acronyms in the file names, there is no indication as to what type of documents these are or the structure and content within.
Additionally, what if the Engineering team wishes to see the date of each scope of work, or the Finance team needs to quickly view the total amounts from all the invoices in their document library, or perhaps the Invoice numbers? Again, the default document library views and columns give little away.
Users would need to open the documents individually to look for the content they needed. Essentially, this is no better than opening an old filing cabinet, taking out the files you need, and trawling through pages to find the information you want. There has to be a better way right?
The Solution
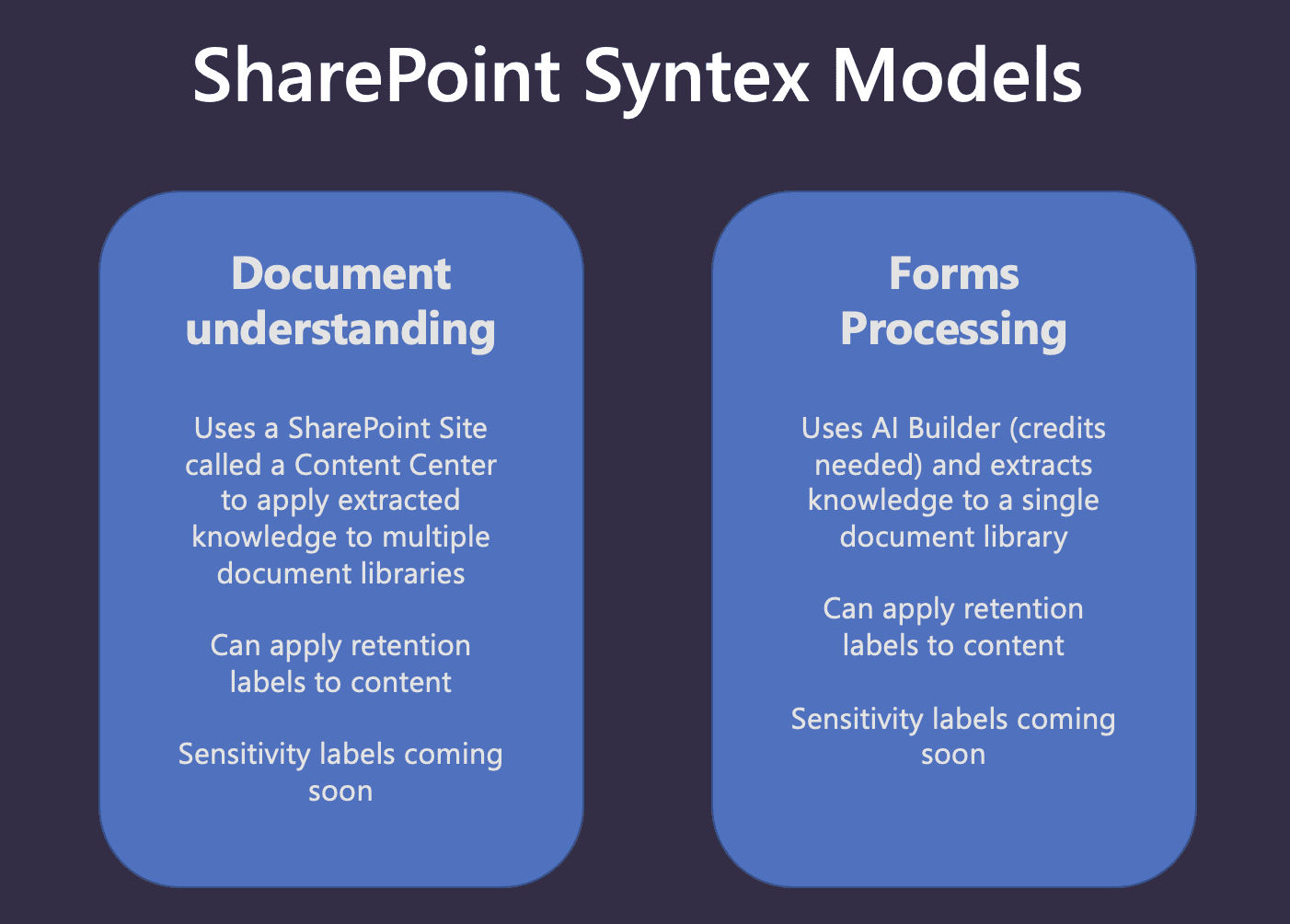
SharePoint Syntex to the rescue! Syntex offers two models (Figure 3), which enable you to classify and extract information from files within SharePoint Online. Let’s explain each model in turn.
Document understanding models are designed to identify specific types of documents and optionally extract information. The models you create may be applied to multiple SharePoint Online document libraries, and the extracted information is presented in columns. Document understanding models are created in a Syntex Content center, which is a SharePoint site created when you first configure SharePoint Syntex for your Microsoft 365 environment. This model is designed to be used with semi-structured file formats such as office documents, where there may be some differences in the general layout, but similar information will be extracted. Typical examples of document types used with document understanding include:
- Letters
- Contracts
- Scopes of work
Users must be assigned a SharePoint Syntex license to use document understanding models in SharePoint Syntex.
Forms processing models work differently to document understanding. A forms processing model is created directly within a unique SharePoint Online document library, and as such may only be applied to that particular library. Like document understanding, forms processing is set up when you first configure SharePoint Syntex for your Microsoft 365 environment, and you choose whether to apply it to all, some, or no document libraries during the initial setup. When you set up a forms processing model in a document library, you are redirected to Microsoft PowerApps AI Builder which Syntex uses to create a model for that library. The AI Builder uses machine learning to identify and extract information from structured or semi-structured documents which include:
- Forms
- Invoices
Users must be assigned a SharePoint Syntex license to use forms processing models in SharePoint Syntex. However, AI Builder credits are also required for this model to work.
Note: If you have 300 or more SharePoint Syntex licenses, you will be allocated one million AI Builder credits. Otherwise, you need to use the AI Builder calculator to determine the AI Builder capacity that you need.
The Model Methodology
So, how does this relate to the document libraries for our Engineering and Finance teams? Well, the Engineering document library contains scoping documents, which best fits with document understanding models, since scopes of work would be considered semi-structured office documents, where there may be some differences in the general layout, but similar content is to be extracted.
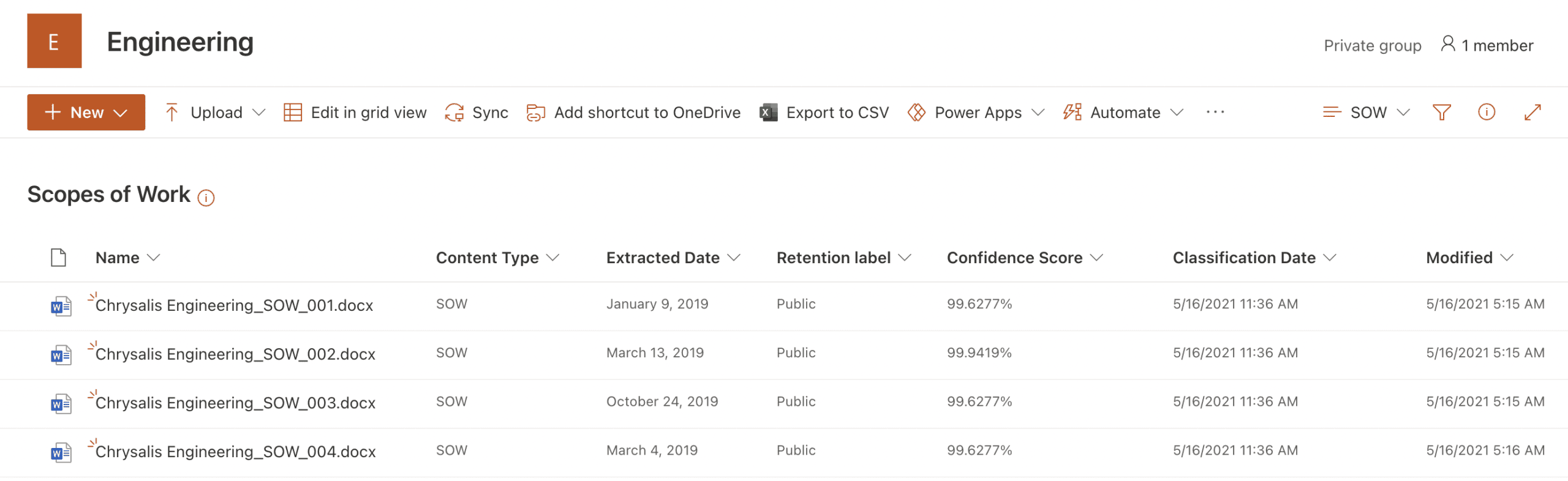
Figure 4 shows a document understanding model applied to the Engineering document library. This model, applied to the library from the SharePoint Syntex Content center, successfully identifies files within the library which should be classified as the content type of SOW, and labels these files accordingly. The model also extracts the date from within the documents and presents it in the Extracted Date column. Note that a retention label has also been applied to content matching the model criteria.
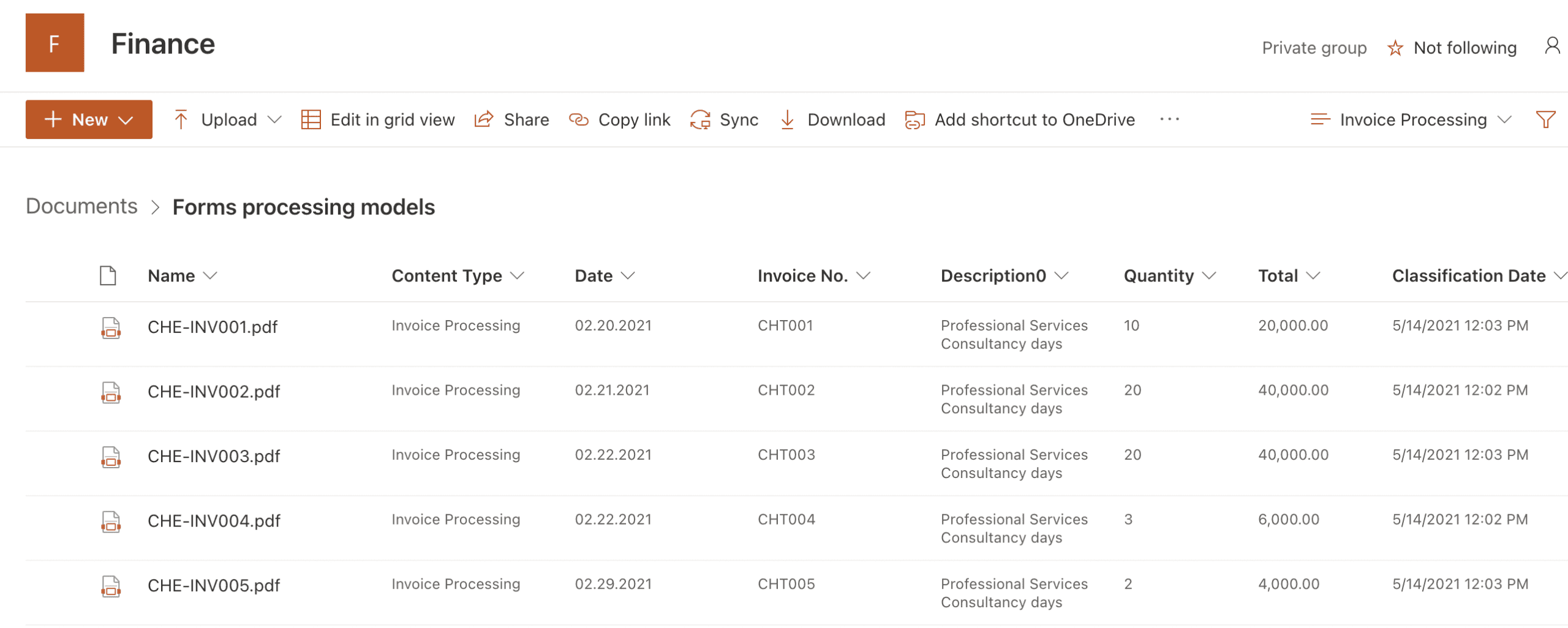
The Finance document library on the other hand contains invoices, which best fits with forms processing models, since invoices would be considered structured documents where the layout is going to remain consistent.
Figure 5 shows a forms processing model applied to the Finance document library. This model, applied directly from the target document library using PowerApps AI builder, creates a flow that successfully identifies files within the library that should be classified as the content type of Invoice Processing, and labels these files accordingly. The model also extracts information from within the invoice, including the date of the invoice, the invoice number, the description, quantity, and total.
Note that while a retention label is not applied to the document library in this example, this is possible with forms processing but was not available in my tenant at the time of writing.
Summary
We have two powerful methods of classifying and extracting content from files within SharePoint Online document libraries using SharePoint Syntex. This post has described the available models in SharePoint Syntex, and shown examples of when to use them, and the results of applying these models.
So far, we have explained the why, and show the before and after. Now we need to dig deeper, and in part two of this series, we will show how to implement SharePoint Syntex document understanding models in detail, including the process of adding and labeling positive and negative files for training, extracting the required content using phrases and patterns, and applying the model to a document library.