



Failover Clustering in Windows Server Technical Preview
Microsoft announced a few features with the launch of the Technical Preview of the next release of Windows Server, due for general availability release in the second half of 2015. More information was released at TechEd Europe 2014 in early November. Failover Clustering is continuing to improve software-defined compute (AKA virtualization or Hyper-V) and software-defined storage solutions. This article will discuss the known new features in Windows Server Technical Preview.
Cluster Operating System Rolling Upgrade
This feature, commonly known as Rolling Upgrade, is the answer to the prayers of every Windows Server cluster administrator, engineer, and consultant since the days of codename Wolfpack, where Windows NT Server 4.0, Enterprise Edition was the first edition of Windows Server to include Microsoft Clustering Services.
Hyper-V administrators, specifically those who realise that they can use the free edition or who purchase Software Assurance that includes upgrade rights benefit, love when new versions of Hyper-V are released because they are filled with loads of new feature goodness. What they have never liked is that they cannot upgrade any Hyper-V clusters that they have deployed. There was no choice but to perform some kind of swing migration from an old cluster to a new cluster. That pain was reduced when migrating from Windows Server 2012 (WS2012) Hyper-V to Windows Server 2012 R2 (WS2012 R2) Hyper-V with Cross-Version Live Migration, which allowed virtual machines to move from a WS2012 host or cluster to a WS2012 R2 host or cluster.
With that said, Cross-Version Live Migration is a one-way move so you had to be committed to the upgrade. Additionally, you still needed to buy new hardware or reduce the size of your older cluster to produce a new cluster.
But, there’s great news, readers! If you are running WS2012 R2 Hyper-V, then you will be able to perform an in-place upgrade of that cluster to the next version of Hyper-V. I should warn you that you will not actually upgrade each node. Microsoft does not like upgrades of Windows Server, even if that’s the way forward for Windows 10. Instead you will drain a host of virtual machines via Live Migration, rebuild that host, add it into the domain, and move on to the next host. The cluster will remain operational in mixed mode (like an Active Directory domain operating in a down-level mode) until all hosts are upgraded and you upgrade the cluster functional level.
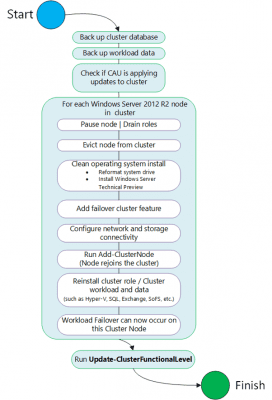
The benefits of a Rolling Upgrade are:
- No need to buy new hardware
- You don’t have to deplete your hosts of nodes to build a new cluster (instead there is a quick rebuild into the existing cluster)
- Virtual machines stay operational and available
Forget copy/paste into command prompt — you can cheer and applaud now! This is a huge result for us Hyper-V customers, and it will make the rumoured frequent updates to Windows Server (post-Threshold) much easier to deploy.
Windows Server vNext Storage Replica
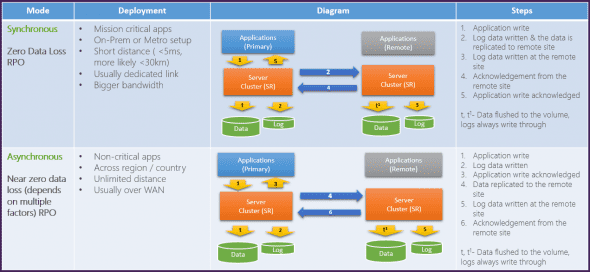
We have software-defined storage since WS2012. We have built-in Hyper-V virtual machine replication since WS2012. And in Windows Server vNext, we are getting Storage Replica, which will give us:
- Synchronous replication over low latency network connections
- Asynchronous replication over longer distances
Storage Replica is storage agnostic, meaning that it doesn’t care what type or brand of storage you use on either site and is block level. You can use Storage Replica either for disaster recovery or for stretch clustering.
An interesting note on this feature is that Microsoft has found another use for SMB 3.0, where it is used as the transport protocol for Storage Replica.
Windows Server vNext Cloud Witness
A feature in Windows Server vNext that is related to disaster recovery is Cloud Witness. A critical requirement of a cluster is the ability to determine quorum. This is complicated when you deploy a stretch cluster, as Storage Replica enables. Traditionally we deployed a file share witness that’s preferably highly available in a third site so that the cluster nodes in site one and site two had quorum. This results in increased costs and complexity, and is a challenge for those that didn’t have a third site. Some enterprising administrators leveraged cloud computing and would deploy a file share witness using virtual machines in a cloud, such as Microsoft Azure, but there was still cost and complexity in doing this.
Windows Server vNext makes deploying a witness for a stretch or multi-site cluster much easier. You will be able to deploy a low-cost Cloud Witness in Azure that will be accessible via HTTPS. This, combined with Storage Replica, is going to make stretch clustering easier and more affordable.

Virtual Machine Compute Resiliency
Let me pose a scenario to you, where a clustered host experiences a transient networking error, such as a switch crash or an administrator pulling an incorrect network cable. Additionally, the other hosts in the cluster can no longer verify that the ‘failed’ host is operational.
And which automatic action would you prefer to happen next? Would you prefer a failover of the virtual machines that might take several minutes to complete? Or, would you prefer to wait a little longer, leaving the virtual machines operational where they are, before initiating a failover?
As it is, Failover Clustering is quite intolerant of outages. And to be honest, most outages are transient; that is, they are things that are brief glitches that sort themselves out. Windows Server vNext will be more tolerant of outages before initiating a failover. So if there is an operational error, clustering won’t reboot the VMs until a certain time has passed, possibly giving that operator a change to re-insert that network cable before the cluster starts failing over and booting up virtual machines. Compute Resiliency will be tuneable by customers so you can make it less or more tolerant.
Note: remember that you should be creating high availability at the guest level with anti-affinity if the guest service was that important in the first place!
Quarantine of Flapping Nodes
If a cluster detects that a single node has been offline too often within a set timeframe, then the cluster will place that host into quarantine. This will cause the host to be drained of virtual machines using Live Migration and also prevents further placement of virtual machines onto that host until it exits quarantine, which the Technical Preview will do after two hours according to a presentation at TechEd Europe 2014. This will prevent further outages to virtual machines if this host is in/out of service due to a fault and it will give administrators a window to remediate the issue.