



Bottlenecks of Modern Data Storage Technologies

We all know that the amount of data both globally in the world and on our personal computers, in particular, is growing constantly – day by day. The need for new data storage technologies exists and they appear with reasonable regularity.
Let’s consider storage technologies focusing on the internal organization of data storage – going from the hardware level of a physical hard drive to the logical level of a file system layout.
Basic Concepts
The problem, which users encountered almost from the moment the personal computers were designed, was that the capacity of a single disk, to put it mildly, was not very large – just imagine that in 1991 IBM introduced a disk with the “unimaginable” size… 1004 MB! The disk was composed of eight 3.5-inch platters.
This situation with disk capacities will always remain the same — hard disk vendors are constantly trying to design larger capacity disks, but the sizes (as well as prices) do not satisfy the user needs.
Back in those days, it became clear that a technology that allows you to combine several disks into a single storage space was needed. That’s how the RAID (Redundant Array of Independent (or Inexpensive) Disks) technology was invented. The technology is based on combining different disks — from different vendors, with different characteristics — into a single storage option using the mirror, stripe, and parity techniques.
- Mirror (RAID1) – array member disks store the identical copies of data. To be honest, a mirror does not provide a large volume of storage, but the technology provides fault tolerance and is widely used in the nested array levels like RAID10.
- Stripe (RAID0) – disk space on the array member disks is cut into the blocks of the same size and then data is written to the blocks according to a specific pattern.
- Parity (RAID5) – disk space is also cut into the blocks but one block in each row is used for storing parity data – a derivative, usually XOR function, calculated over data blocks. This approach ensures redundancy, allowing a storage system to survive a disk failure without data loss.
All other storage technologies are, by and large, variations of the RAID technology. Let’s look more closely at some of the most popular ones.
Drobo BeyondRAID
The Drobo developers designed their own technology to be used in the Drobo devices – Drobo BeyondRAID. The technology was released a long time ago, in 2007, and uses the same RAID technique. However, this is not a “pure” RAID – RAID arrays in Drobo are created over the regions, which are several tens of megabytes in size, rather than over the whole hard drive, as is done in a traditional RAID. Next, the regions are combined into larger structures, called zones, from which file system clusters are then allocated.
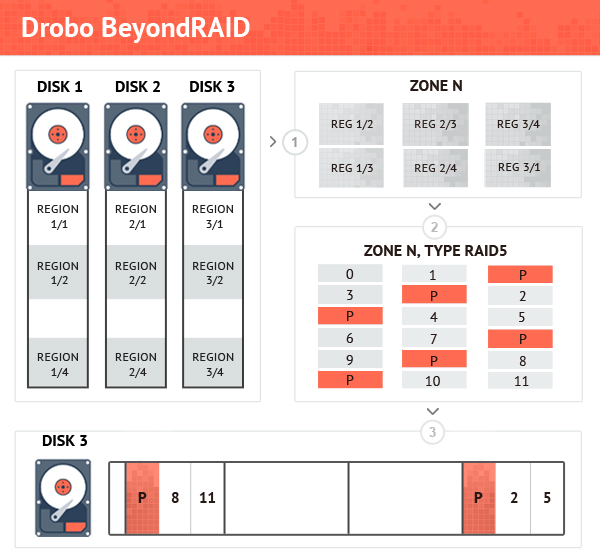
Sounds difficult but still not bad…but there’s one more thing – a cluster map storing information on which cluster is located in which zone. The very cluster map is stored in a special zone as well — the map is fully integrated into the Drobo layout.
If the cluster map is lost or overwritten, data recovery doesn’t make sense because the cluster size is too small – all you get by analyzing data on a Drobo disk pack are a lot of meaningless data fragments.
Storage Spaces
In 2012, Microsoft released the Storage Spaces technology, allowing you to combine disks of different sizes into the pools, on which then it is possible to create spaces of five types — simple, mirror, 3-way mirror, parity, and double parity.
In Storage Spaces, disk space on the disks is cut into 256 MB slabs, which are then combined into spaces of a given type using the appropriate RAID technique. Similar to the Drobo BeyondRAID having a cluster map as a bottleneck, there is a table storing information on which slabs are combined into which RAIDs. If the table is lost, it is very difficult to restore a Storage Spaces layout. In the case of a mirror or parity space, there is at least theoretical background to recover a lost RAID configuration; for a simple layout, the configuration is lost irreversibly.

Another more interesting observation is that the modern trend is pools and spaces of 30-50 TB in size. Taking into account the slab size of 256 MB and 8-column layout, we have a maximum of 256 * 7 = 1.8 GB (for a parity space) per RAID. It is not difficult to imagine that the number of such micro-RAIDs in a Storage Spaces pool can easily reach tens of thousands!
NAS Devices
Network Attached Storage is a storage device that allows you to combine several hard disks into one large storage space, which is then connected to a computer network. The simplest NAS layout uses the following scheme – physical disks are combined into two RAIDs – one RAID is a small RAID1 for storing NAS firmware and another large RAID (usually RAID5) is for user data. These RAIDs are created by the Linux md-RAID driver and typically one of the Linux file systems is used, usually ext or XFS. The scheme implies using disks of the same size – you can still use disks of different sizes but the overall capacity will be tightly tied to the size of the smallest disk.
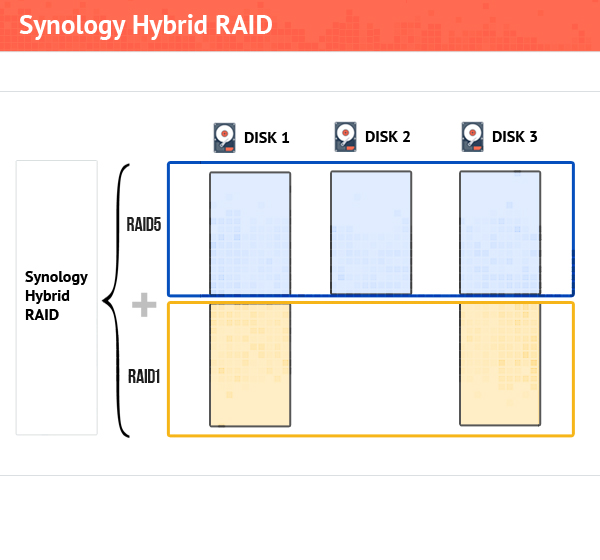
Nowadays, schemes of combining disks are more complicated. They allow using disks of different sizes without disk space loss and, more than that, it is possible to replace disks with the larger ones without full-scale rebuilding. One example is Synology NASes, where you can use completely different disks thanks to the Synology Hybrid RAID technology.
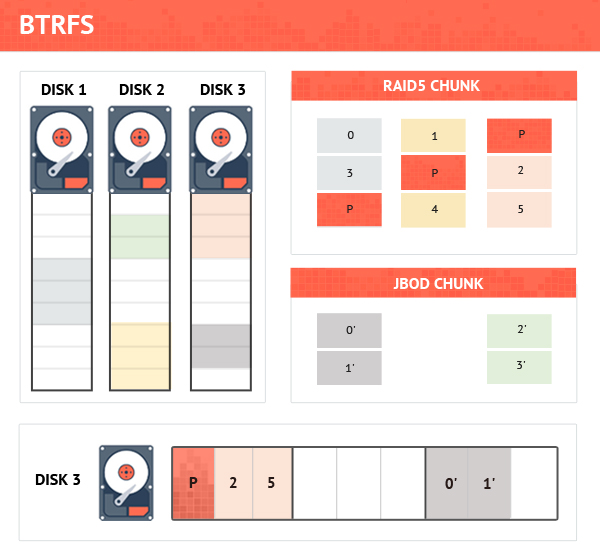
At this, NAS vendors did not stop and first NETGEAR and then Synology started using a new file system – BTRFS. The file system differs from a “pure” file system, which knows nothing about the underlying physical layout, in that it combines both the functions of the disk space allocator and the file system driver.
Inside, BTRFS operates with not very large of blocks (1GB for user data and minimum 4 MB for metadata), which are called chunks. Chunks are made from the blocks allocated on the physical disks and combined into larger continuous blocks using the RAID technology.
Until recently, chunks were combined into the blocks using the JBOD technique, but now BTRFS supports RAID5 and RAID6 with the 64 KB stripe size. With BTRFS, it is possible to have multi-layer RAID configurations like those where there is a main RAID5 created over the physical disks and multiple sub-RAIDs created over chunks allocated from the main RAID.
The information on how chunks are composed is stored in the file system metadata. Should the metadata be lost, nothing can be recovered.
ReFS
ReFS filesystem was released simultaneously with the Microsoft Storage Spaces technology. The first ReFS version was quite simple – a file record stored the file attribute data such as file size, creation/modification times, and the information about the file content location. A directory record contained information about files and folders belonging to the directory.
In 2016, Microsoft released ReFS of the next generation. Surprisingly, the modern ReFS now has an analogous of a cluster map. On the one hand, there are several copies of the map stored on a volume; on the other hand, file deletion results in discarding the corresponding records in the cluster map. Deleted file data can still be on the disks but you cannot get it extracted because cluster location is not available any longer.
Conclusion
Obviously, with increasing disk capacity, new schemes of storing data are needed. The modern technologies still use the old good RAID, but there is a tendency to have many small RAIDs along with the cluster maps. RAID configuration metadata and cluster maps are the main bottlenecks of the modern storage technologies.
Written by Elena Pakhomova of www.ReclaiMe.com, offering data recovery solutions for a wide variety of data storage technologies.
Related Article: